Chapter 9 - Advanced Algorithms¶
We return again to visualization algorithms. This chapter describes algorithms that are either more complex to implement, or less widely used for 3D visualization applications. We retain the classification of algorithms as either scalar, vector, tensor, or modelling algorithms.
9.1 Scalar Algorithms¶
As we have seen, scalar algorithms often involve mapping scalar values through a lookup table, or creating contour lines or surfaces. In this section, we examine another contouring algorithm, dividing cubes, which generates contour surfaces using dense point clouds. We also describe carpet plots. Carpet plots are not true 3D visualization techniques, but are widely used to visualize many types of scalar data. Finally, clipping is another important algorithm related to contouring, where cells are cut into pieces as a function of scalar value.
Dividing Cubes¶
Dividing cubes is a contouring algorithm similar to marching cubes [Cline88]. Unlike marching cubes, dividing cubes generates point primitives as compared to triangles (3D) or lines (2D). If the number of points on the contour surface is large, the rendered appearance of the contour surface appears "solid."q To achieve this solid appearance, the density of the points must be at or greater than screen resolution. (Also, the points must be rendered using the standard lighting and shading equations used in surface rendering.)
The motivation for dividing cubes is that rendering points is much faster than rendering polygons. This varies depending upon rendering hardware/software. Special purpose hardware has been developed to render shaded points at high speed. In other systems, greater attention has been placed on polygon rendering, and the rendering speed differences are not so great. Also, certain geometric operations such as clipping and merging data are simple operations with points. Comparable operations with polygons are much more difficult to implement.
One disadvantage of creating contours with dense point clouds is that magnification of the surface (via camera zooming, for example) reveals the disconnected nature of the surface. Thus, the point set must be constructed for maximum zoom, or constructed dynamically based on the relative relationship between the camera and contour.
Although dividing cubes was originally developed for volume datasets, it is possible to adapt the algorithm to other dataset types by subdividing in parametric coordinates. Our presentation assumes that we are working with volumes.
Figure 9-1 provides an overview of the dividing cubes algorithm. Like other contouring algorithms, we first choose a contour value. We begin by visiting each voxel and select those through which the isosurface passes. (The isosurface passes through a voxel when there are scalar values both above and below the contour value.) We also compute the gradient at each voxel point for use in computing point normals.
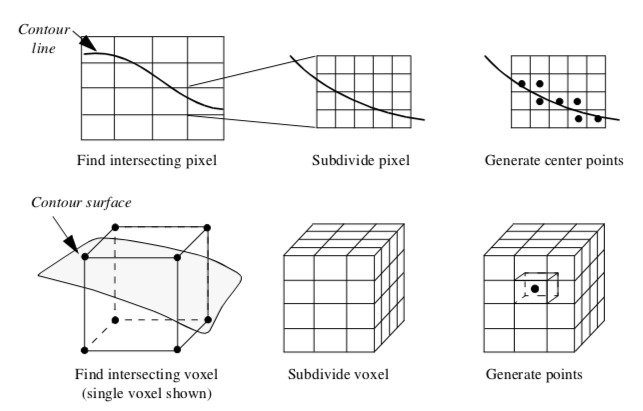
After selecting a voxel that the isosurface passes through, the voxel is subdivided into a regular grid of n1 \times n2 \times n3 subvoxels. The number of divisions is controlled by the width of a voxel w_i in combination with screen resolution R. The screen resolution is defined as the distance between adjacent pixels in world coordinates. We can express the number of divisions ni along the coordinate axes x_i as w_i
where the quotient is rounded up to the nearest integer. The scalar values at the subpoints are generated using the interpolation functions for a voxel (see Figure 8-10). Then we determine whether the contour passes through each subvoxel. If it does, we simply generate a point at the center of the subvoxel and compute its normal using the standard interpolation functions.
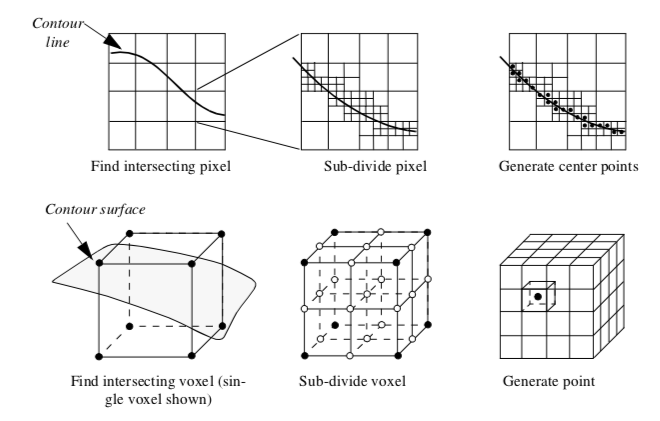
An interesting variation on this algorithm is a recursive implementation as shown in Figure 9-2. Instead of subdividing the voxel directly (i.e., procedurally) into a regular grid we recursively divide the voxel (similar to octree decomposition). The voxel is subdivided regularly creating eight subvoxels and 19 new points (12 midedge points, 6 midface points, and 1 midvoxel point). The scalar values at the new points are interpolated from the original voxel using the trilinear interpolation functions. The process repeats for each subvoxel if the isosurface passes through it. This process continues until the size of the subvoxel is less than or equal to screen resolution. In this case, a point is generated at the center of the subvoxel. The collection of all such points composes the dividing cubes isosurface.
The advantage of the recursive implementation is that the subdivision process terminates prematurely in those regions of the voxel where the contour cannot pass. On the other hand, the recursive subdivision requires that the voxel subdivision occurs in powers of two. This can generate far more points than the procedural implementation.
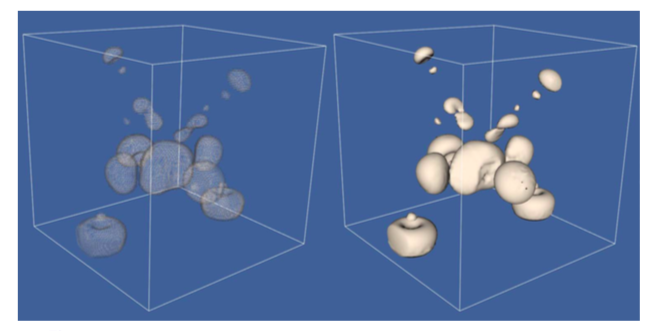
Figure 9-3 shows two examples of dividing cubes isosurfaces. The contour surface on the left consists of 50,078 points. Because the points are not generated at display resolution, it is possible to see through the contour surface. The second contour surface on the right is composed of 2,506,989 points. The points are generated at display resolution, and as a result the contour surface appears solid.
As Figure 9-1 and Figure 9-2 show, the points generated by dividing cubes do not lie exactly on the contour surface. We can determine the maximum error by examining the size of the terminal subvoxels. Assume that a terminal subvoxel is a cube, and that the length of the side of the cube is given by l. Then the maximum error is half the length of the cube diagonal, or l 3 / 2.
Carpet Plots¶
A common data form is a 2D image dataset with associated scalar data. Carpet plots can visualize data in this form. A carpet plot is created by warping a 2D surface in the direction of the surface normal (or possibly some user-defined direction). The amount of warping is controlled by the scalar value, possibly in combination with a scale factor. Carpet plots are similar to the vector displacement plots (see "Displacement Plots" in Chapter 4).
Although carpet plots are typically applied to image data, they can be used to visualize datasets composed of 2D structured grids or 2D unstructured grids. In their basic form carpet plots can be used to visualize only three variables: two surface position coordinates and a scalar value. However, it is common to introduce another variable by using color mapping on the surface.
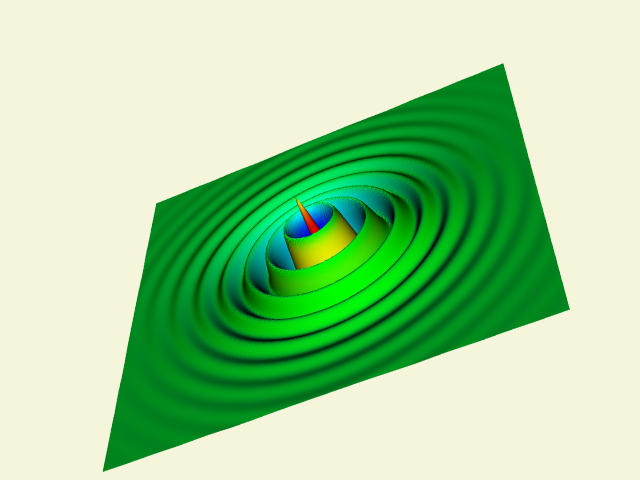
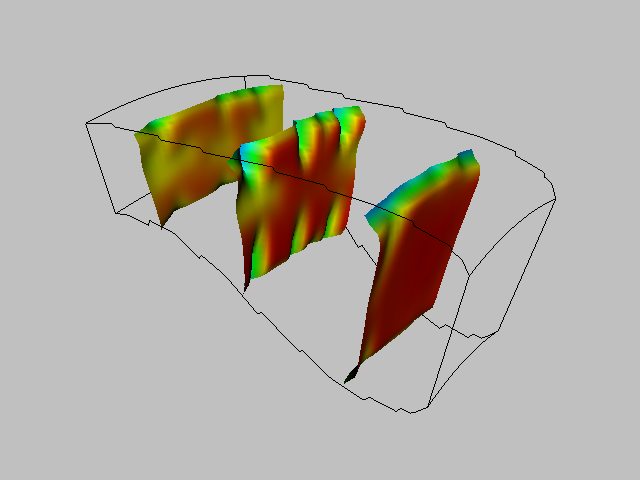
The function values are used to warp the surface while the function derivatives are used to color it. Figure 9-4(b) shows a carpet plot that visualizes flow energy in a structured grid. Both displacement and color are used to show the energy values. Although this figure is similar to Figure 6-14(b) there are some important differences. Figure 6-14(b) displays vector data whereas Figure 9-4(b) displays scalar data. Figure 9-4(b) deforms the surface in the direction of surface normal (or possibly a user-defined direction). The vector data (i.e., vector orientation) controls the direction of deformation in Figure 6-14(b).
Clipping With Scalar Fields¶
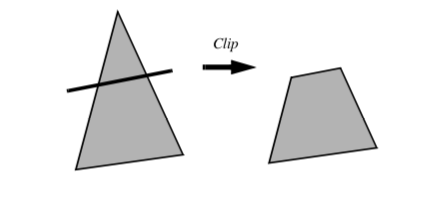
Clipping is a common graphics operation that limits the extent of a polygon so that it does not lie outside the view frustrum (see "Cameras" in Chapter 3). Figure 9-5 shows a triangle before and after clipping with an infinite plane. The clip operation transforms a polygon into a polygon. Clipping can also be a powerful modeling tool. Clipping part of a structure can reveal internal details of the surface or other parts contained within the surface. Objects can be split into pieces and the pieces can be individually moved and controlled.
We can do clipping with arbitrary implicit functions using a variation of the "marching" primitives discussed in "Contouring" in Chapter 6. We illustrate the technique for triangles.
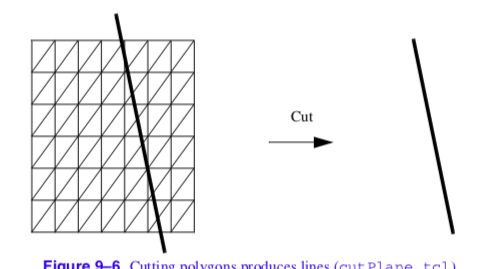
Recall that marching triangles transforms triangles into lines that approximate a scalar value called the isovalue. This is accomplished using the inside/outside relationship that each vertex has with respect to some scalar value. For our purposes here, we use a scalar value that represents the signed distance of the triangle vertex to a plane. This infinite plane, described by an implicit function of the form F(x, y, z) = n_{xx} + n_{yy} + n_{zz} - d = 0, partitions space into two infinite half spaces. All points with negative scalar values lie on one side of the plane and all with positive values lie on the other side. Figure 9-6 shows a finite plane represented by a grid of triangles. The thick line shows the infinite plane defined by F(x,y,z) = x + y + z - c = 0. The cut algorithm described in "Cutting" in Chapter 6 creates a set of lines using the contour operations specific to each cell primitive. In this example, the triangle's contour operator extracts lines that lie on the intersection of the infinite plane and the triangles that comprise the finite plane. The contour operation for a triangle uses the eight cases shown in Figure 9-7 to contour or "cut" each triangle appropriately. `
Clipping transforms polygons into polygons. We do clipping with a modified case table for the triangle that outputs polygons shown in Figure 9-8. In VTK, each polygonal data cell has a different case table to define the clip operation. Applying the clip algorithm to the polygonal data in Figure 9-9 using the same scalar field generated with a plane equation produces a new set of triangles.
Formulating clipping using scalar fields permits more sophisticated operations. Clipping can use scalar data that is computed or scalar data that is part of a polygonal dataset's point attributes.
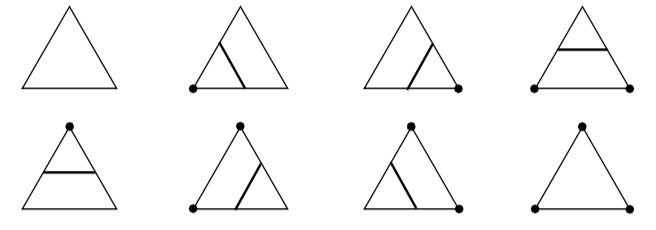
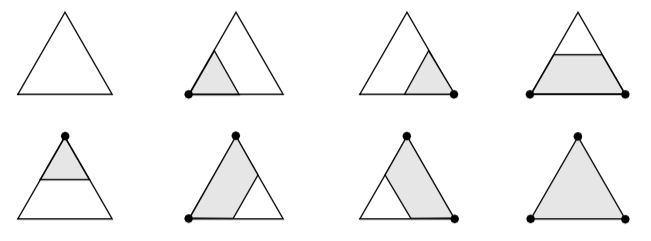
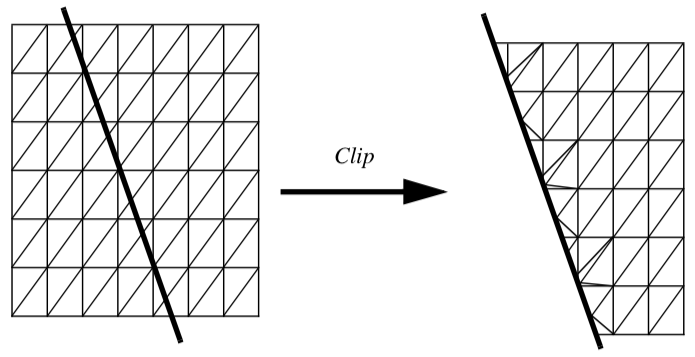
Figure 9-10 shows a scanned image that is first converted to a quadrilateral mesh with vertex scalar values set to the scanned image intensity. Clipping this quadrilateral mesh with a value equal to 1/2 the maximum intensity of the scanned image produces a polygonal model show in Figure 9-10.

9.2 Vector Algorithms¶
In Chapter 6 - Fundamental Algorithms we showed how to create simple vector glyphs and how to integrate particles through a vector field to create streamlines. In this section we extend these concepts to create streamribbons and streampolygons. In addition, we introduce the concept of vector field topology, and show how to characterize a vector field using topological constructs.
Streamribbons and Streamsurfaces¶
Streamlines depict particle paths in a vector field. By coloring these lines, or creating local glyphs (such as dashed lines or oriented cones), we can represent additional scalar and temporal information. However, these techniques can convey only elementary information about the vector field. Local information (e.g., flow rotation or derivatives) and global information (e.g., structure of a field such as vortex tubes) is not represented. Streamribbons and streamsurfaces are two techniques used to represent local and global information.
A natural extension of the streamline technique widens the line to create a ribbon. The ribbon can be constructed by generating two adjacent streamlines and then bridging the lines with a polygonal mesh. This technique works well as long as the streamlines remain relatively close to one another. If separation occurs, so that the streamlines diverge, the resulting ribbon will not accurately represent the flow, because we expect the surface of the ribbon to be everywhere tangent to the vector field (i.e., definition of streamline). The ruled surface connecting two widely separated streamlines does not generally satisfy this requirement.
The streamribbon provides information about important flow parameters: the vector vorticity and flow divergence. Vorticity \Omega is the measure of rotation of the vector field, expressed as a vector quantity: a direction (axis of rotation) and magnitude (amount of rotation). Streamwise vorticity \Omega is the projection of \vec{\omega} along the instantaneous velocity vector, \vec{v}. Said another way, streamwise vorticity is the rotation of the vector field around the streamline defined as follows.
The amount of twisting of the streamribbon approximates the streamwise vorticity. Flow divergence is a measure of the "spread" of the flow. The changing width of the streamribbon is proportional to the cross-flow divergence of the flow.
A streamsurface is a collection of an infinite number of streamlines passing through a base curve. The base curve, or rake, defines the starting points for the streamlines. If the base curve is closed (e.g., a circle) the surface is closed and a streamtube results. Thus, streamribbons are specialized types of streamsurfaces with a narrow width compared to length.
Compared to vector icons or streamlines, streamsurfaces provide additional information about the structure of the vector field. Any point on the streamsurface is tangent to the velocity vector. Consequently, taking an example from fluid flow, no fluid can pass through the surface. Streamtubes are then representations of constant mass flux. Streamsurfaces show vector field structure better than streamlines or vector glyphs because they do not require visual interpolation across icons.
Streamsurfaces can be computed by generating a set of streamlines from a user-specified rake. A polygonal mesh is then constructed by connecting adjacent streamlines. One difficulty with this approach is that local vector field divergence can cause streamlines to separate. Separation can introduce large errors into the surface, or possibly cause self-intersection, which is not physically possible.
Another approach to computing streamsurfaces has been taken by Hultquist [Hultquist92]. The streamsurface is a collection of streamribbons connected along their edges. In this approach, the computation of the streamlines and tiling of the streamsurface is carried out concurrently. This allows streamlines to be added or removed as the flow separates or converges. The tiling can also be controlled to prevent the generation of long, skinny triangles. The surface may also be "torn", i.e., ribbons separated, if the divergence of the flow becomes too high.
Stream Polygon¶
The techniques described so far provide approximate measures of vector field quantities such as streamwise vorticity and divergence. However, vector fields contain more information than these techniques can convey. As a result, other techniques have been devised to visualize this information. One such technique is the stream polygon [Schroeder91], which serves as the basis for a number of advanced vector and tensor visualization methods. The stream polygon is used to visualize local properties of strain, displacement, and rotation. We begin by describing the effects of a vector field on the local state of strain.
Nonuniform vector fields give rise to local deformation in the region where they occur. If the vector field is displacement in a physical medium such as a fluid or a solid, the deformation consists of local strain (i.e., local distortion) and rigid body motion. To mathematically describe the deformation, we examine a 3D vector \vec{v} = (u, v, w) at a specified point x = (x, y, z). Using a first order Taylor's series expansion about x, we can express the local deformation eij as
where \epsilon_{ij} is the local strain and \omega_{ij} is the local rotation. Note that these variables are expressed as 3 \times 3 tensors. (Compare this equation to that given in Figure 6-20. Note that this equation and the following Equation 9-5 differ in their off-diagonal terms by a factor of 1/2. This is because Figure6-20 expresses engineering shear strain which is used in the study of elasticity. Equation 9-5 expresses a tensor quantity and is mathematically consistent.)
The local strain is expressed as a combination of the partial derivatives at x as follows.
The terms on the diagonal of \epsilon_{ij} are the normal components of strain. The off-diagonal terms are the shear strain. The local rigid-body rotation is given by Equation 9-6 can also be represented using tensor notation as
where \omega is the vorticity vector referred to in the previous section. The vorticity, or local rigid body rotation is then
For the reader unfamiliar with tensor notation, this presentation is certainly less than complete. However, the matrices in Equation 9-5 and Equation 9-6 directly translate into visual form, which will help clarify the concepts presented here. Referring to Figure 9-11, the normal strain, shear strain, and rigid body motion create distinct deformation modes. These modes combine to produce the total deformation. Modes of normal strain cause compression or extension in the direction perpendicular to a surface, while shear strains cause angular distortions. These strains combined with rigid body rotation around an axis yield the total strain at a point.
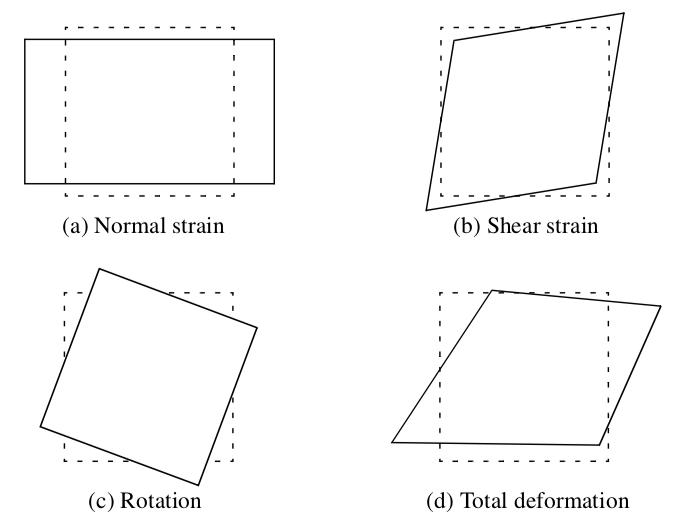
The essence of the stream polygon technique is to show these modes of deformation. A regular n-sided polygon (Figure 9-12) is placed into a vector field at a specified point and then deformed according to the local strain. The components of strain may be shown separately or in combination. The orientation of the normal of the polygon is arbitrary. However, it is convenient to align the normal with the local vector. Then the rigid body rotation about the vector is the streamwise vorticity, and the effects of normal and shear strain are in the plane perpendicular to a streamline passing through the point.
The stream polygon offers other interesting possibilities. The stream polygon may be swept along a trajectory, typically a streamline, to generate tubes. The radius of the tube r can be modified according to some scalar function. One application is to visualize fluid flow. In incompressible flow with no shear, the radius of the tube can vary according to the scalar function vector magnitude. Then the equation
represents an area of constant mass flow. As a result, the tube will thicken as the flow slows and narrow as the velocity increases. Each of the n sides of the tube can be colored with a different scalar function, although for visual clarity, at most, one or two functions should be used.
The streamtubes generated by the streampolygon and the streamtubes we described in the previous section are not the same. The streampolygon does not necessarily lie along a streamline. If it does, the streampolygon represents information at a point, while the streamtube is an approximation constructed from multiple streamlines. Also, the radial variation in the tubes constructed from streampolygon sweeps do not necessarily relate to mass flow since the radius in a streampolygon can be tied to an arbitrary scalar variable.
Vector Field Topology¶
Vector fields have a complex structure characterized by special features called critical points [Globus91] [Helman91]. Critical points are locations in the vector field where the local vector magnitude goes to zero and the vector direction becomes undefined. At these points the vector field either converges or diverges, and/or local circulation around the point occurs.
Critical points lie in dataset cells where the u, v, and w components of the vector field each pass through zero. These points are located using an iterative search procedure such as the bi-section technique. Each iteration evaluates the cell interpolation function until the zero vector is found. Once a critical point is found, its local behavior is determined from the matrix of partial derivatives.
This is because at the critical point the velocity is zero, and the vector field can be approximated by a first-order expansion of partial derivatives [Helman91]
The matrix of partial derivatives J can be written in vector notation as \partial u \partial v \partial w
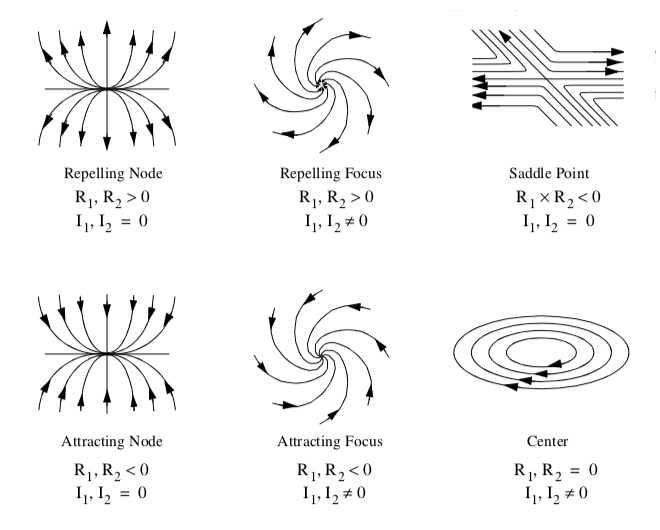
and is referred to as the Jacobian. The behavior of the vector field in the vicinity of a critical point is characterized by the eigenvalues of J. The eigenvalues consist of an imaginary and real component. The imaginary component describes the rotation of the vector field around the critical point, while the real part describes the relative attraction or repulsion of the vector field to the critical point. In two dimensions the critical points are as shown in Figure 9-13.
A number of visualization techniques have been developed to construct vector field topology from an analysis of critical points. These techniques provide a global understanding of the field, including points of attachment and detachment and field vortices. Using a fluid flow analogy, points of attachment and detachment occur on the surface of an object where the tangential component of the vector field goes to zero, and the flow is perpendicular to the surface. Thus, streamlines will begin or end at these points. There is no common definition for a vortex, but generally speaking, vortices are regions of relatively concentrated vorticity (e.g., flow rotation). The study of vortices is important because they represent areas of energy loss, or can have significant impact on downstream flow conditions (e.g., trailing vortices behind large aircraft).
One useful visualization technique creates vector field skeletons that divide the vector field into separate regions. Within each region, the vector field is topologically equivalent to uniform flow. These skeletons are created by locating critical points, and then connecting the critical points with streamlines. In 3D vector field analysis this technique can be applied to the surface of objects to locate lines of flow separation and attachment and other important flow features. Also, in general 3D flow, the regions of uniform flow are separated by surfaces, and creation of 3D flow skeletons is a current research topic.
Vortex visualization is another area of current research. One technique computes the helicitydensity
This is a scalar function of the vector dot product between the vorticity and the local vector. Large positive values of H_d result in right-handed vortices, while large negative values indicate lefthanded vortices. Helicity-density can be conveniently shown using isosurfaces, which gives an indication for the location and structure of a vortex.
9.3 Tensor Algorithms¶
In Chapter 6 - Fundamental Algorithms we saw that 3 \times 3 real symmetric tensors can be characterized by the eigenvalues and eigenvectors of the tensor. Recall that we can express the eigenvectors of the system as
where \vec{e}_i is a unit vector in the direction of the eigenvalue, and \lambda_i are the eigenvalues. Thus, we can decompose a 3 \times 3 real symmetric tensor field into three vector fields, each field defined by one of the three eigenvectors described in Equation 9-13. We call these vector fields eigenfields, since they are derived from the eigenvectors of the tensor field.
Decomposition of the tensor field in this fashion provides additional insight into visualizing 3 \times 3 real symmetric tensors. We can directly use the vector field visualization techniques presented previously or use variations of them. One such technique is a novel extension of the streampolygon technique, the method of hyperstreamlines.
Hyperstreamlines¶
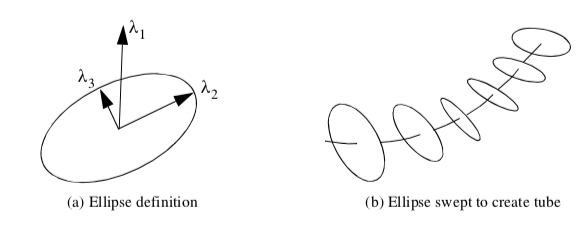
Hyperstreamlines are constructed by creating a streamline through one of the three eigenfields, and then sweeping a geometric primitive along the streamline [Delmarcelle93]. Typically, an ellipse is used as the geometric primitive, where the remaining two eigenvectors define the major and minor axes of the ellipse (Figure 9-14). Sweeping the ellipse along the eigenfield streamline results in a tubular shape. Another useful generating geometric primitive is a cross. The length and orientation of the arms of the cross are controlled by two of the eigenvectors. Sweeping the cross results in a helical shape since the eigenvectors (and therefore cross arms) will rotate in some tensor fields.
Figure 9-15 shows an example of hyperstreamlines. The data is from a point load applied to a semi-infinite domain. Compare this figure to Figure 6-22 that used tensor ellipsoids tov visualize the same data. Notice that there is less clutter and more information available from the hyperstreamline visualization.
9.4 Modelling Algorithms¶
Visualizing Geometry¶
One of the most common applications of visualization is to view geometry. We may have a geometric representation of a part or complex assembly (perhaps designed on a CAD system) and want to view the part or assembly before it is manufactured. While viewing geometry is better addressed in text on computer graphics, often there is dataset structure we wish to view in the same way. For example, we may want to see data mapped on a particular portion of the dataset, or view the structure of the dataset itself (e.g., view a finite element mesh).
Three-dimensional datasets have a surface and interior. Typically we want to visualize the surface of the dataset or perhaps a portion of the interior. (Note: volume rendering is a different matter - see "Volume Rendering" in Chapter 7. To visualize the dataset we must extract a portion of the dataset topology/geometry (and associated data) as some form of surface primitives such as polygons. If the surface of the dataset is opaque, we may also wish to eliminate occluded interior detail.
We have already seen how structured datasets, such as image data or structured grids, have a natural i-j-k coordinate system that allow extraction of points, lines, and planes from the interior of the dataset (see "Structured Coordinate System" in Chapter 8). For example, to extract the fifth -iplane from a structured grid of dimensions (i_m, j_m, k_m), we specify the data extents using (4, 4, 0, (j_m - 1), 0, (k_m 1)) (assuming zero-offset addressing).
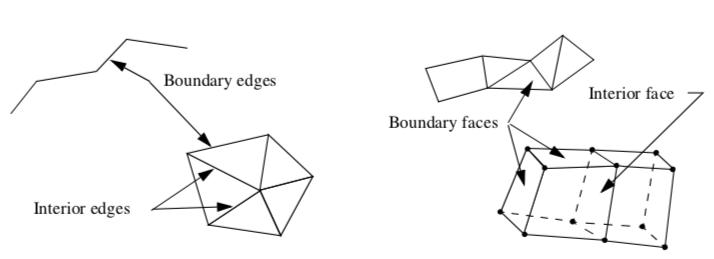
More generally, we can extract boundary edges and faces from a dataset. A boundary edge isan 1D cell type (e.g., line or polyline), or the edge of a 2D cell used by only that single cell. Similarly, a boundary face is a 2D cell type (e.g., polygon, triangle strip) or the face of a 3D cell used by only that single cell (Figure 9-16). We can obtain this information using the topological operators of the previous chapter. Cells of dimensions two or less are extracted as is, while boundary edges and faces are determined by counting the number of cell neighbors for a particular topological boundary (i.e., edge or face neighbors). If there are no neighbors, the edge or face is a boundary edge or face, and is extracted.
Using these techniques we can view the structure of our dataset. However, there are also situations where we want more control in the selection of the data. We call this data extraction.
Data Extraction¶
Often we want to extract portions of data from a dataset. This may be because we want to reduce the size of the data, or because we are interested in visualizing only a portion of it.
Reducing dataset size is an important practical capability, because visualization data size can be huge. By reducing data size, reductions in computation and memory requirements can be realized. This results in better interactive response.
We also may need to reduce data size in order to visualize the important features of a large dataset. This can be used to reduce image clutter and improve the effectiveness of the visualization. Smaller data size also enables the visualization user to navigate through and inspect data more quickly relative to larger datasets. Next we describe two techniques to extract data. One is based on geometry extraction, and the other is based on data thresholding, or thresholding.
Geometry Extraction. Geometry extraction selects data based on geometric or topological characteristics. A common extraction technique selects a set of points and cells that lie within a specified range of ids. A typical example is selecting all cells having ids between 0-100, or all cells using point ids 250-500. Finite element analysts use this method frequently to isolate the visualization to just a few key regions.
Another useful technique called spatial extraction, selects dataset structure and associated data attributes lying within a specified region in space. For example, a point and radius can be used to select (or deselect) data within an enclosing sphere. Implicit functions are particularly useful tools for describing these regions. Points that evaluate negative are inside the region, while points outside the region evaluate positive; thus, cells whose points are all positive are outside the region, and cells whose points are all negative are inside the region.
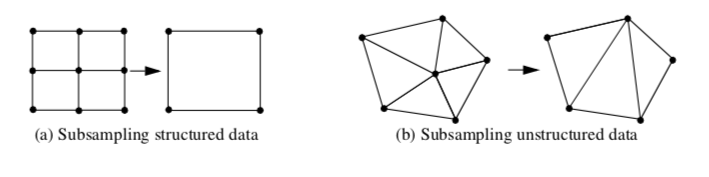
Subsampling (Figure 9-17) is a method that reduces data size by selecting a subset of the original data. The subset is specified by choosing a parameter n, specifying that every nth data point is to be extracted. For example, in structured datasets such as image data and structured grids, selecting every nth point produces the results shown in Figure 9-17(a).
Subsampling modifies the topology of a dataset. When points or cells are not selected, this leaves a topological "hole." Dataset topology must be modified to fill the hole. In structured data, this is simply a uniform selection across the structured i-j-k coordinates. In unstructured data (Figure 9-17(b)), the hole must be filled in by using triangulation or other complex tessellation schemes. Subsampling is not typically performed on unstructured data because of its inherent complexity.
A related technique is data masking. In data masking we select every nth cell that at a minimum leaves one or more topological "holes" in the dataset. Masking also may change the topology of the dataset, since partial selections of cells from structured datasets can only be represented using unstructured grids. Masking is typically used to improve interactive performance or to quickly process portions of data.
Thresholding. Thresholding extracts portions of a dataset data based on attribute values. For example, we may select all cells having a point with scalar value between (0,1) or all points having a velocity magnitude greater than 1.0.
Scalar thresholding is easily implemented. The threshold is either a single value that scalar values are greater than or less than, or a range of values. Cells or points whose associated scalar values satisfy the threshold criteria can be extracted. Other dataset attribute types such as vectors, normals, or tensors can be extracted in similar fashion by converting the type to a single scalar value. For example, vectors can be extracted using vector magnitude, and tensors using matrix determinate.
A problem with both geometry extraction and thresholding is that the approaches presented thus far extract "atomic" pieces of data, that is, a complete cell. Sometimes the cell may lie across the boundary of the threshold. In this case the cell must be clipped (see "Clipping With Scalar Fields" in this Chapter) and only a portion of the cell is extracted.
Probing¶
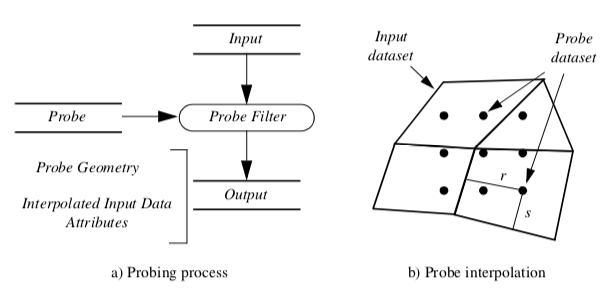
Probing obtains dataset attributes by sampling one dataset (the input) with a set of points (the probe) as shown in Figure 9-18(a). Probing is also called "resampling." Examples include probing an input dataset with a sequence of points along a line, on a plane, or in a volume. The result of the probing is a new dataset (the output) with the topological and geometric structure of the probe dataset, and point attributes interpolated from the input dataset. Once the probing operation is completed, the output dataset can be visualized with any of the appropriate techniques described in this text.
Figure 9-18(b) illustrates the details of the probing process. For every point in the probe dataset, the location in the input dataset (i.e., cell, subcell, and parametric coordinates) and interpolation weights are determined. Then the data values from the cell are interpolated to the probe point. Probe points that are outside the input dataset are assigned a nil (or appropriate) value. This process repeats for all points in the probe dataset.
Probing can be used to reduce data or to view data in a particular fashion.
-
Data is reduced when the probe operation is limited to a subregion of the input dataset, or the number of probe points is less than the number of input points.
-
Data can be viewed in a particular fashion by sampling on specially selected datasets. Using a probe dataset consisting of a line enables x-y plotting along a line, or using a plane allows surface color mapping or line contouring.
Probing must be used carefully or errors may be introduced. Under-sampling data in a region can miss important high-frequency information or localized data variations. Oversampling data, while not creating error, can give false confidence in the accuracy of the data. Thus the sampling frequency should have a similar density as the input dataset, or if higher density, the visualization should be carefully annotated as to the original data frequency.
One important application of probing converts irregular or unstructured data to structured form using a volume of appropriate resolution as a probe to sample the unstructured data. This is useful if we use volume rendering or other volume visualization techniques to view our data.
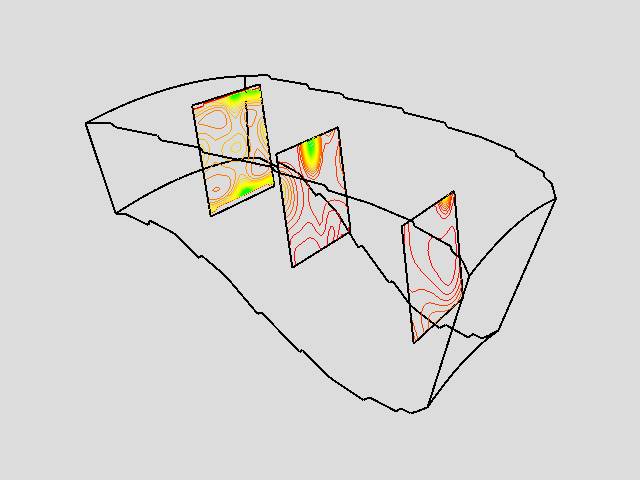
Figure 9-19 shows an example of three probes. The probes sample flow density in a structured grid. The output of the probes is passed through a contour filter to generate contour lines. As this figure illustrates, we can be selective with the location and extent of the probe, allowing us to focus on important regions in the data.
Triangle Strip Generation¶
Triangle strips are compact representations of triangle polygons as described in "Triangle Strip" in Chapter 5. Many rendering libraries include triangle strips as graphics primitives because they are a high-performance alternative to general polygon rendering.
Visualization and graphics data is often represented with triangles. Marching cubes, for example, generates thousands and potentially millions of triangles to represent an isosurface. To achieve greater performance in our visualizations, we can convert triangle polygons into triangle strips. Or, if data is represented using polygons, we can first triangulate the polygons and then create triangle strips.
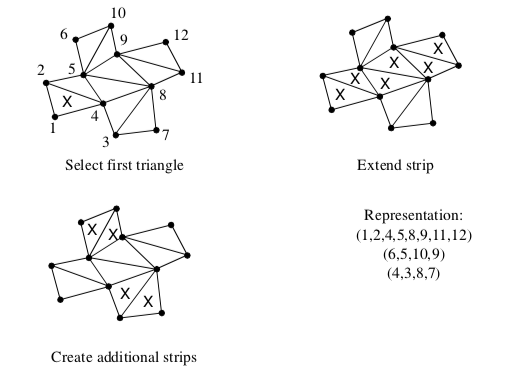
A simple method to generate triangle strips uses greedy gathering of triangles into a strip (Figure 9-20). The method proceeds as follows. An "unmarked" triangle is found to initialize the strip - unmarked triangles are triangles that have not yet been gathered into a triangle strip. Starting with the initial triangle, the strip may grow in one of three directions, corresponding to the three edges of the triangle. We choose to grow the strip in the direction of the first unmarked neighbor triangle we encounter. If there are no unmarked neighbors the triangle strip is complete; otherwise, the strip is extended by adding triangles to the list that satisfy triangle strip topology. The strip is grown until no unmarked neighbor can be found. Additional strips are then created using the same procedure until every triangle is marked.
The length of the triangle strips varies greatly depending on the structure of the triangle mesh.
Figure 9-21(a) shows triangle strips each of 390 triangles in length from a dataset that was originally structured. Such a case is an exception: unstructured triangle meshes typically average about 5-6 triangles per strip (Figure 9-21(b)). Even so, the memory savings are impressive. A triangle strip of length 6 requires 8 points to represent, while 8 triangles require 24 points, for a memory savings of 66.7 percent. Rendering speed may be greatly affected, too, depending upon the capabilities of the rendering system.
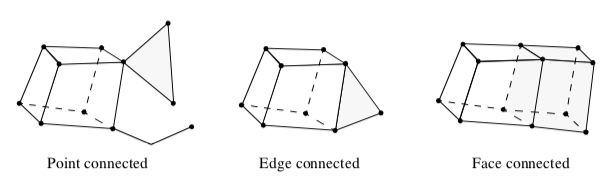
Connectivity¶
Intercell connectivity is a topological property of datasets. Cells are topologically connected when they share boundary features such as points, edges, or faces (Figure 9-22). Connectivity is useful in a number of modeling applications, particularly when we want to separate out "parts" of a dataset.
One application of connectivity extracts a meaningful portion of an isosurface. If the isosurface is generated from measured data such as an MRI or CT scan, it likely contains "noise" or unimportant anatomical structure. Using connectivity algorithms, we can separate out the part of the isosurface that we desire, either by eliminating noise or undesirable anatomical structure. Figure 9-23 is an example where a 2D surface of interest (e.g., an isocontour) is extracted from a noisy signal.

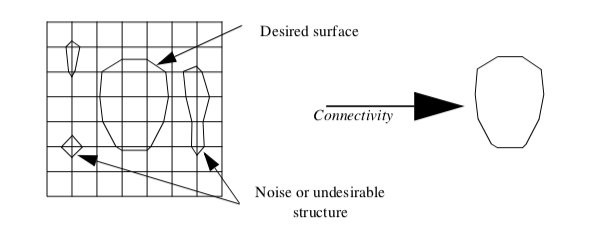
Connectivity algorithms can be implemented using a recursive visit method. We begin by choosing an arbitrary cell and mark it "visited". Then, depending upon the type of connectivity desired (i.e., point, edge, face), we gather the appropriate neighbors and mark them visited. This process repeats recursively until all connected cells are visited. We generally refer to such a set of connected cells as a connected "surface" even though the cells may be of a topological dimension other than two.
To identify additional connected surfaces we locate another unvisited cell and repeat the processes described previously. We continue to identify connected surfaces until every cell in the dataset is visited. As each connected surface is identified, it is assigned a surface number. We can use this number to specify the surfaces to extract or we can specify "seed" points or cells and extract the surfaces connected to them.
In some cases the recursion depth of the connectivity algorithm becomes larger than the computer system can manage. In this case, we can specify a maximum recursion depth. When this depth is exceeded, recursion is terminated and the current cells in the recursion are used as seeds to restart the recursion.
Polygon Normal Generation
Gouraud and Phong shading (see Chapter 3 - Computer Graphics Primer) can improve the appearance of rendered polygons. Both techniques require point normals. Unfortunately polygonal meshes do not always contain point normals, or data file formats may not support point normals. Examples include the marching cubes algorithm for general datasets (which typically will not generate surface normals) and the stereo lithography file format (does not support point normals). Figure 9-24(a) shows a model defined from stereo-lithography format. The faceting of the model is clearly evident.
To address this situation we can compute surface normals from the polygonal mesh. A simple approach follows. First, polygon normals are computed around a common point. These normals are then averaged at the point, and the normal is renormalized (i.e., n = 1 ) and associated with the point. This approach works well under two conditions.
-
The orientation of all polygons surrounding the point are consistent as shown in Figure 9-24(b). A polygon is oriented consistently if the order of defining polygon points is consistent with its edge neighbors. That is, if polygon p is defined by points (1,2,3), then the polygon edge neighbor p23 must use the edge (2,3) in the direction (3,2). If not consistent, then the average point normal may be zero or not accurately represent the orientation of the surface. This is because the polygon normal is computed from a cross product of the edges formed by its defining points.
-
The angular difference in surface normals between adjacent polygons is small. Otherwise, sharp corners or edges will have a washed out appearance when rendered, resulting in an unsatisfactory image (Figure 9-24(c)).
To avoid these problems we adopt a more complex polygon normal generation algorithm. This approach includes steps to insure that polygons are oriented consistently, and an edge-splitting scheme that duplicates points across sharp edges.
To orient edges consistently we use a recursive neighbor traversal. An initial polygon is selected and marked "consistent." For each edge neighbor of the initial polygon, the ordering of the neighbor polygon points is checked - if not consistent, the ordering is reversed. The neighbor polygon is then marked "consistent." This process repeats recursively for each edge neighbor until all neighbors are marked "consistent". In some cases there may be more than one connected surface, so that the process may have to be repeated until all polygons are visited.
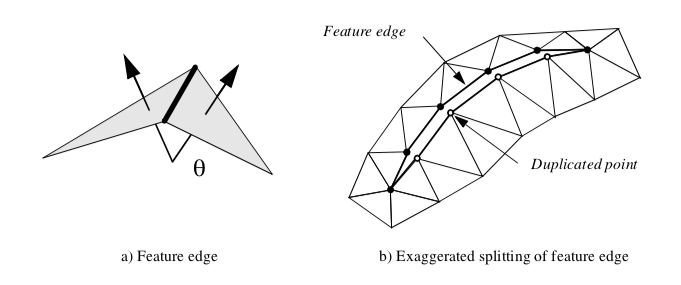
A similar traversal method splits sharp edges. A sharp edge is an edge shared by two polygons whose normals vary by a user-specified feature angle. The feature angle between two polygons is the angle between their normals (Figure 9-25(a)). When sharp edges are encountered during the recursive traversal, the points along the edge are duplicated, effectively disconnecting the mesh along that edge (Figure 9-25(b)). Then, when shared polygon normals are computed later in the process, contributions to the average normal across sharp edges is prevented.
On some computers limitations on recursion depth may become a problem. Polygonal surfaces can consist of millions of polygons, resulting in large recursion depth. As a result, the depth of recursion can be specified by the user. If recursion depth exceeds the specified value, the recursion halts and the polygons on the boundary of the recursion become seeds to begin the process again.
Figure 9-24(d) shows the result of the advanced normal generation technique with a feature angle of 60 degrees. Sharp edges are well defined and curved areas lack the faceting evident in the original model. The figure is shown with Gouraud shading.

Decimation¶
Various data compression techniques have been developed in response to large data size. The UNIX utilities compress/uncompress and the PC utility zip compress data files. The MPEG compression algorithm compresses video sequences. These techniques may be loss-less, meaning that no data is lost between the compression/decompression steps, or lossy, meaning that data is lost during compression. The utilities compress/uncompress and zip are loss-less, while MPEG is lossy.
In graphics, data compression techniques have been developed as well. The subsampling methods we saw earlier in this chapter are an example of simple data compression techniques for visualization data. Another emerging area of graphics data compression is polygon reduction techniques.
Polygon reduction techniques reduce the number of polygons required to model an object. The size of models, in terms of polygon count, has grown tremendously over the last few years. This is because many models are created using digital measuring devices such as laser scanners or satellites. These devices can generate data at tremendous rates. For example, a laser digitizer can generate on the order of 500,000 triangles in a 15-second scan. Visualization algorithms such as marching cubes also generate large numbers of polygons: one to three million triangles from a 5123 volume is typical.
One polygon reduction technique is the decimation algorithm [Schroeder92a]. The goal of the decimation algorithm is to reduce the total number of triangles in a triangle mesh, preserving the original topology and forming a good approximation to the original geometry. A triangle mesh is a special form of a polygonal mesh, where each polygon is a triangle. If need be, a polygon mesh can be converted to a triangle mesh using standard polygon triangulation methods.
Decimation is related to the subsampling technique for unstructured meshes described in Figure 9-17(b). The differences are that
-
decimation treats only triangle meshes not arbitrary unstructured grids;
-
the choice of which points to delete is a function of a decimation criterion, a measure of the local error introduced by deleting a point; and
-
the triangulation of the hole created by deleting the point is carried out in a way as to preserve edges or other important features.
Decimation proceeds by iteratively visiting each point in a triangle mesh. For each point, three basic steps are carried out (Figure 9-26). The first step classifies the local geometry and topology in the neighborhood of the point. The classification yields one of the five categories shown in the figure: simple, boundary, complex, edge, and corner point. Based on this classification, the second step uses a local error measure (i.e., the decimation criterion) to determine whether the point can be deleted. If the criterion is satisfied, the third step deletes the point (along with associated triangles), and triangulates the resulting hole. A more detailed description of each of these steps and example applications follow.
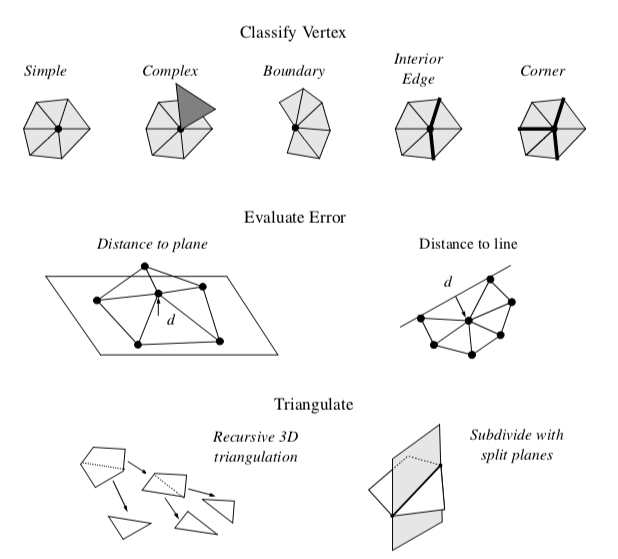
Point Classification. The first step of the decimation algorithm characterizes the local geometry and topology for a given point. The outcome of classification determines whether the vertex is a potential candidate for deletion, and if it is, which criteria to use.
Each point may be assigned one of five possible classifications: simple, complex, boundary, interior edge, or corner vertex. Examples of each type are shown in Figure 9-26.
A simple point is surrounded by a complete cycle of triangles, and each edge that uses the point is used by exactly two triangles. If the edge is not used by two triangles, or if the point is used by a triangle not in the cycle of triangles, then the point is complex. These are nonmanifold cases.
A point that is on the boundary of a mesh, that is, within a semicycle of triangles, is a boundary point.
A simple point can be further classified as an interior edge or corner point. These classifications are based on the local mesh geometry. If the surface normal angle between two adjacent triangles is greater than a specified feature angle, then a feature edge exists (see Figure 9-25(a)). When a point is used by two feature edges, the point is an interior edge point. If one, three, or more feature edges use the point, the point is a corner point.
Complex and corner vertices are not deleted from the triangle mesh; all other vertices become candidates for deletion.
Decimation Criterion. Once we have a candidate point for deletion, we estimate the error that would result by deleting the point and then replacing it (and its associated triangles) with another triangulation. There are a number of possible error measures; but the simplest are based on distance measures of local planarity or local colinearity (Figure 9-26).
In the local region surrounding a simple point, the mesh is considered nearly "flat," since there are by definition no feature edges. Hence, simple points use an error measure based on distance to plane. The plane passing through the local region can be computed either using a leastsquares plane or by computing an area-averaged plane.
Points classified as boundary or interior edge are considered to lay on an edge, and use a distance to edge error measure. That is, we compute the distance that the candidate point is from the new edge formed during the triangulation process.
A point satisfies the decimation criterion d if its distance measure is less than d. The point can then be deleted. All triangles using the point are deleted as well, leaving a "hole" in the mesh. This hole is patched using a local triangulation process.
Triangulation. After deleting a point, the resulting hole must be retriangulated. Although the hole, defined by a loop of edges, is topologically two dimensional, it is generally non-planar, and therefore general purpose 2D triangulation techniques cannot be used. Instead, we use a special recursive 3D divide-and-conquer technique to triangulate the loop.
Triangulation proceeds as follows. An initial split plane is chosen to divide the loop in half and create two subloops. If all the points in each subloop lie on opposite sides of the plane, then the split is a valid one. In addition, an aspect ratio check insures that the loop is not too long and skinny, thereby resulting in needle-like triangles. The aspect ratio is the ratio between the length of the split line to the minimum distance of a point in the subloop to the split plane. If the candidate split plane is not valid or does not satisfy the aspect ratio criterion, then another candidate split plane is evaluated. Once a split plane is found, then the subdivision of each subloop continues recursively until a subloop consists of three edges. In this case, the subloop generates a triangle and halts the recursion.
Occasionally, triangulation fails because no split plane can be found. In this case, the candidate point is not deleted and the mesh is left in its original state. This poses no problem to the algorithm and decimation continues by visiting the next point in the dataset.
Results. Typical compression rates for the decimation algorithm range from 2:1 to 100:1, with 10:1 a nominal figure for "large" (i.e., 105 triangles) datasets. The results vary greatly depending upon the type of data. CAD models typically reduce the least because these models have many sharp edges and other detailed features, and the CAD modellers usually produce minimal triangulations. Terrain data, especially if relatively flat regions are present, may reduce at rates of 100:1.


Figure 9-27 shows two applications of decimation to laser digitized data and to a terrain model of Honolulu, Hawaii. In both cases the reduction was on the order of 90 percent for a 10:1 compression ratio. Wireframe images are shown to accentuate the density of the polygonal meshes. The left-hand image in each pair is the original data; the right-hand image is the decimated mesh.
Notice the gradations in the decimated mesh around features of high curvature. The advantage of decimation, as compared to subsampling techniques, is that the mesh is adaptively modified to retain more details in areas of high curvature.
Advanced Techniques. Polygon reduction is an active field of research. Many powerful algorithms beyond the decimation algorithm have been presented (see "Bibliographic Notes" in this Chapter). Although we cannot cover the field in its entirety in this section, there are two notable trends worth addressing. First, progressive schemes [Hoppe96] allow incremental transmission and reconstruction of triangle meshes - this is especially important for Web-based geometry visualization. Second, recent algorithms modify the topology of the mesh [He96] [Popovic97] [Schroeder97]. This feature is essential towards obtaining arbitrary levels of mesh reduction.
A progressive mesh is a series of triangle meshes M_ii related by the operations
where \vec{M} and M^n represent the mesh at full resolution, and M^0 is a simplified base mesh. The critical characteristic of progressive meshes is that is possible to choose the mesh operations in such a way to make them invertible. Then the operations can be applied in reverse order (starting with the base mesh M^0)
to obtain a mesh of desired reduction level (assuming that the reduction level is less than the base mesh M^0).
One such invertible operator is an edge collapse and its inverse is the edge split shown in Figure 9-28(a). Each collapse of an interior mesh edge results in the elimination of two triangles (or one triangle if the collapsed vertex is on a boundary). The operation is represented by five values
where v_s is the vertex to collapse/split, v_t is the vertex being collapsed to / split from, and v_l and v_r are two additional vertices to the left and right of the split edge. These two vertices in conjunction with v_s and v_t define the two triangles deleted or added. A represents vertex attribute information, which at a minimum contains the coordinates x of the collapsed / split vertex v_s. (Note: in the context of the decimation algorithm, the edge collapse operator replaces the recursive triangulation process.)
While progressive meshes allow us to compactly store and transmit triangle meshes, the problem remains that the size of the base mesh is often larger than desired reduction level. Since in some applications we wish to realize any given level, we want the base mesh to contain no triangles
(some vertices are necessary to initiate the edge split operations). To address this problem, the invertible edge collapse/split operator - which is topology preserving - is extended with a vertex split/merge operator. The vertex split/merge operator modifies the topology of the mesh and allows arbitrary levels of reduction.
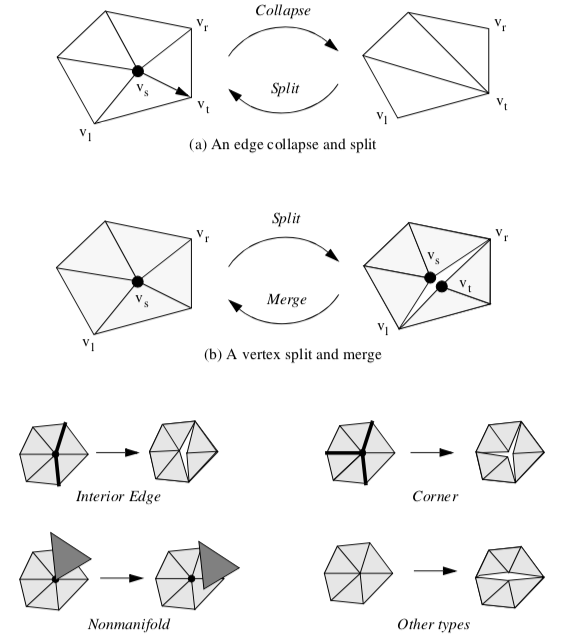
A mesh split occurs when we replace vertex vs with vertex vt in the connectivity list of one or more triangles that originally used vertex vs (Figure 9-28(b)). The new vertex vt is given exactly the same coordinate value as vs. Splits introduce a "crack" or "hole" into the mesh. We prefer not to split the mesh, but at high decimation rates this relieves topological constraint and enables further decimation. Splitting is only invoked when a valid edge collapse is not available, or when a vertex cannot be triangulated (e.g., a nonmanifold vertex). Once the split operation occurs, the vertices vs and vt are re-inserted into the priority queue.
Different splitting strategies are used depending on the classification of the vertex (Figure 9-28(c)). Interior edge vertices are split along the feature edges, as are corner vertices.
Nonmanifold vertices are split into separate manifold pieces. In any other type of vertex splitting occurs by arbitrarily separating the loop into two pieces. For example, if a simple vertex cannot be deleted because a valid edge collapse is not available, the loop of triangles will be arbitrarily divided in half (possibly in a recursive process).
Like the edge collapse/split, the vertex split/merge can also be represented as a compact operation. A vertex split/merge operation can be represented with four values
The vertices v_l and v_r define a sweep of triangles (from v_r to v_l ) that are to be separated from the original vertex vs (we adopt a counter-clockwise ordering convention to uniquely define the sweep of triangles).
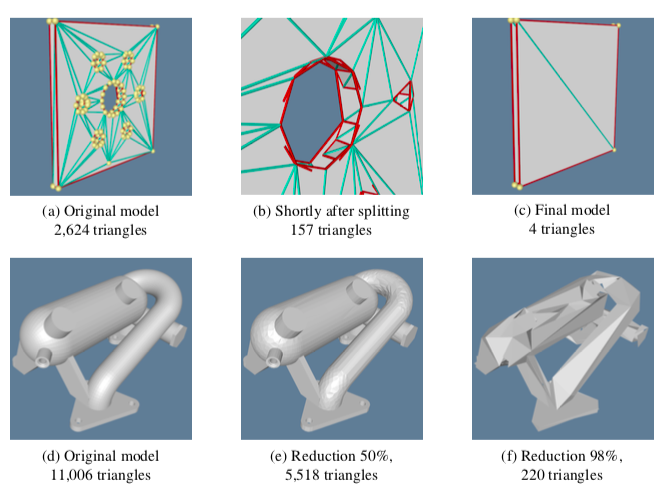
Figure 9-29 shows the results of applying the topology modifying progressive mesh algorithm to two sets of data. In Figure 9-29(a-c), a thin plate with holes is decimated (the darker lines show split edges). The middle image in the sequence shows the limits of topology on the algorithm. It is only when the topology of the mesh is allowed to be modified that the final level of reduction is possible. Figure 9-29(d-f) shows the same algorithm applied to CAD data.
Mesh Smoothing¶
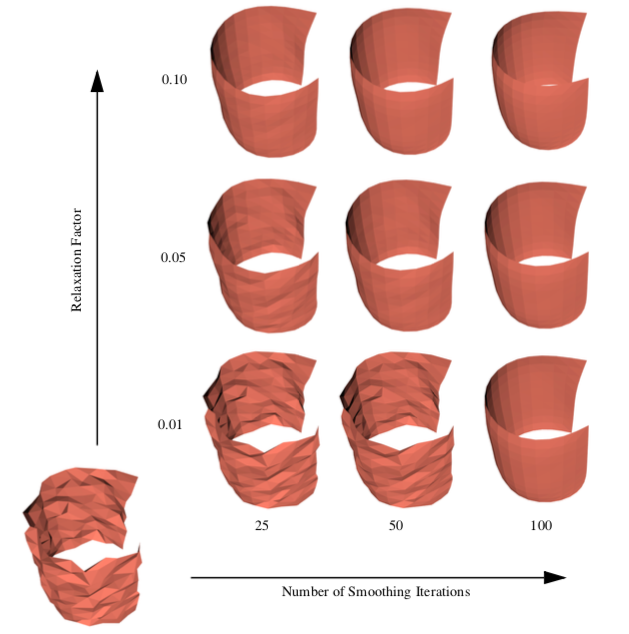
Mesh smoothing is a technique that adjusts the point coordinates of a dataset. The purpose of mesh smoothing is to improve the appearance of a mesh, and/or improve the shape of dataset cells. During smoothing the topology of the dataset is not modified, only the geometry. Applications of mesh smoothing include improving the appearance of isosurfaces, or as a modelling tool to remove surface noise. The appearance of models can be dramatically improved by applying mesh smoothing. Figure 9-30 is an example of smoothing applied to analytic surface (a semicylinder) with a random surface distortion (smoothCyl.tcl).
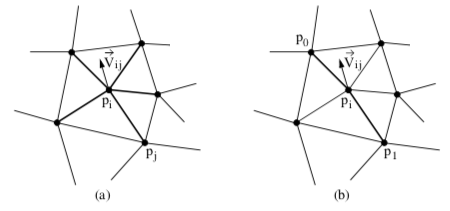
A simple, yet effective technique is Laplacian smoothing. The Laplacian smoothing equation for a point p_i at position x_i is given by
where x_i + 1 is the new coordinate position, and x_j are the positions of points p_j "connected" to p_i, and \lambda is a user-specified weight. Geometrically this relation is depicted in Figure 9-31(a). Here the vertex p_i is connected to the surrounding points p_j via edges. The equation expresses that the new position x_i + 1 is offset from the original position x_i plus the average vector \vec{V}_{ij} multiplied by \lambda. Typically, the factor \lambda is a small number (e.g., 0.01), and the process is executed repeatedly (e.g., 50-100 iterations). Notice that the overall effect of smoothing is to reduce the high frequency surface information. The algorithm will reduce surface curvature and tend to flatten thesurface.
Besides adjusting the number of iterations and smoothing factor, smoothing can be controlled by modifying the connections between p_i and its surrounding points pj. For example, if p_i lies along a fold or sharp edge in the mesh, we may want to only use the two edge end points to compute the smoothing vector \vec{V}_ij, limiting the motion of p_i along the edge (Figure 9-31(b)). We can also anchor p_i to prevent any motion. Anchoring is useful for points that are located on "corners" or other special features such as nonmanifold attachments. One benefit of anchoring and controlling point connectivity is that we can limit the amount of shrinkage in the mesh. It also tends to produce better overall results. (In Figure 9-30 the boundary points of the surface are constrained to move along the boundary, while the points at sharp corners are anchored.)
Although Laplacian smoothing works well in most cases, there are applications of Laplacian smoothing that can badly damage the mesh. Large numbers of smoothing iterations, or large smoothing factors, can cause excessive shrinkage and surface distortion. Some objects, like spheres or the cylinder shown in Figure 9-30, will lose volume with each iteration, and can even shrink to a point. In rare cases it is possible for the mesh to pull itself "inside-out." Situations like this occur when the average vector moves pi across a mesh boundary, causing some of the attached triangles to overlap or intersect.
Mesh smoothing is particularly useful when creating models that do not require high accuracy. As we have seen, smoothing modifies point coordinates and, therefore, surface geometry. Use smoothing to improve the appearance of models, but characterize error carefully if you are going to measure from a smoothed surface. Alternatively, you may want to design your own smoothing algorithms that better fit the underlying data.
Swept Volumes and Surfaces¶
Consider moving an object (e.g., your hand) over some path (e.g., raise your hand). How can we visualize this motion? The obvious answer is to form a time-animation sequence as the hand is moved. But what if we wish to statically represent the motion as well as the space that is traversed by the hand? Then we can use swept surfaces and swept volumes.
A swept volume is the volume of space occupied by an object as it moves through space along an arbitrary trajectory. A swept surface is the surface of the swept volume. Together, swept volumes and swept surfaces can statically represent the motion of objects.
Past efforts at creating swept surfaces and volumes have focused on analytical techniques. The mathematical representation of various 3D geometric primitives (e.g., lines, polygons, splines) was extended to include a fourth dimension of time (the path). Unfortunately, these approaches have never been practically successful, partly due to mathematical complexity and partly due to problem degeneracies.
Degeneracies occur when an n-dimensional object moves in such a way that its representation becomes (n-1)-dimensional. For example, moving a plane in the direction of its normal, sweeps out a 3D "cubical" volume. Sweeping the plane in a direction perpendicular to its normal, however, results in a degenerate condition, since the plane sweeps out a 2D "rectangle."
Instead of creating swept surfaces analytically, numerical approximation techniques can be used [Schroeder94]. Implicit modeling provides the basis for an effective technique to visualize object motion via swept surfaces and volumes. The technique is immune to degeneracies and can treat any geometric representation for which a distance function can be computed, such as the VTK cell types.
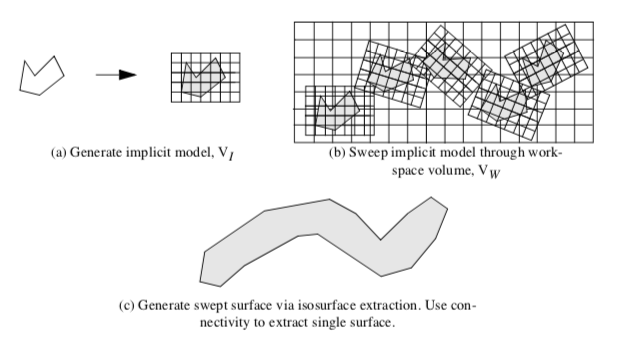
The technique to generate swept surfaces and volumes using an implicit modeling approach proceeds as follows. The geometric model, or part, and a path describing the parts motion, or sweep trajectory ST, must be defined. Then we use the following steps as depicted in Figure 9-32.
-
Generate an implicit model from the part. This results in an implicit representation in the form of a volume. We call this the implicit model V_I.
-
Construct another volume, the workspace volume V_W, that strictly bounds V_I as it moves along the path ST. Then sweep V_I through V_W by moving in small steps, \delta x, along ST. At each step, s, sample V_I with the workspace volume V_W. We use a boolean union operation to perform the sampling.
-
Extract isosurface, or offset surface(s) from V_W using a contouring algorithm such as marching cubes.
-
Step3 may create multiple connected surfaces. If a single surface is desired, use connectivity to extract the single "largest" surface (in terms of number of triangles). This surface is an approximation to the swept surface, and the volume it encloses is an approximation to the swept volume.
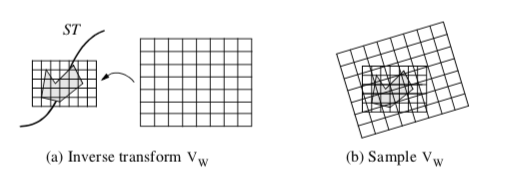
There are a few points that require additional explanation. This algorithm uses two volumes, the implicit model and the workspace volume. Both are implicit models, but the workspace volume is used to accumulate the part as it moves along the sweep trajectory. In theory, the part could be sampled directly into the workspace volume to create the implicit model of the swept surface. Performance issues dictate that the implicit model is sampled into the workspace volume. This is because it is much faster to sample the implicit model of the part rather than the part itself, since computing the distance function from a part that may consist of tens of thousands of cells is relatively timeconsuming, compared to sampling the implicit model V_I.
Sampling V_I is depicted in Figure 9-33. The sweep trajectory is defined by a series of transformation matrices ST = {t_1, t_2,..., t_m}. As the part moves along ST, interpolation is used to compute an inbetween transformation matrix t. Sampling is achieved by inverse transforming VW into the local space of V_I using t. Then, similar to the probe operation described in "Probing" in this Chapter, the points of V_W are transformed by the inverse of the transformation matrix t-1, and used to interpolate the distance values from the implicit model V_I.
Because we are dealing with an implicit modeling technique, parts with concave features can generate multiple surfaces. As discussed in "Connectivity" in this Chapter, the connectivity algorithm is used to separate out the swept surface. This final surface is an approximation to the actual swept surface, since we are sampling the actual geometric representation on an array of points (i.e., the implicit model), and then sampling the implicit model on another volume (i.e., the workspace volume). Also, stepping along the sweep trajectory generates errors proportional to the step size \deltax.
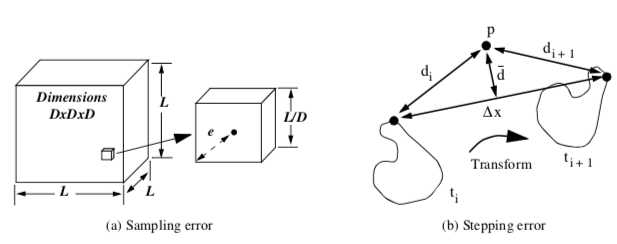
These errors can be characterized as follows (Figure 9-34). Given a voxel size L/D, where L is the edge length of the volume, and D is the dimension of the volume (assumed uniform for convenience), the maximum sampling error is
The error due to stepping, which includes both translation and rotational components, is bounded by \delta x / 2, where \delta x is the maximum displacement of any point on the implicit model at any given translational step. Combining these terms for sampling both volumes and the error due to stepping, the total error is
where the subscripts I and W refer to the implicit model and workspace volume, respectively.
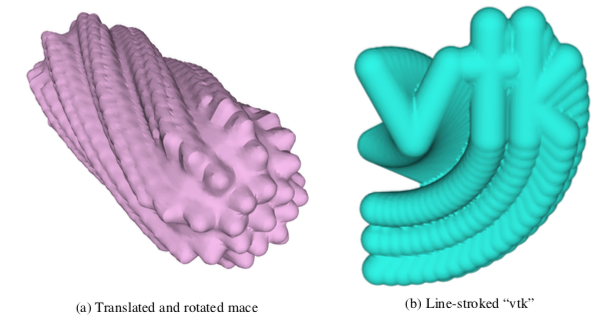
To show the application of this algorithm, we have generated swept surfaces for the letters "VTK" and the "mace" model as shown in Figure 9-35.
We have purposely chosen a step size to exaggerate the stepping error. Using more steps would smooth out the surface "bumps" due to stepping. Also, the appearance of the surface varies greatly with the selected isosurface value. Larger values give rounder, smoother surfaces. If you use small values near zero (assuming positive distance function) the surface may break up. To correct this you need to use a higher resolution work-space or compute negative distances. Negative distances are computed during the implicit modeling step by negating all points inside the original geometry. Negative distances allow us to use a zero isosurface value or to generate internal offset surfaces. Negative distances can only be computed for closed (i.e., manifold) objects.
Visualizing Unstructured Points¶
Unstructured point datasets consist of points at irregular positions in 3D space. The relationship between points is arbitrary. Examples of unstructured point datasets are visualizing temperature distribution from an array of (arbitrarily) placed thermocouples, or rainfall level measured at scattered positions over a geographic region.
Unlike image data and structured grids, or even unstructured grids, unstructured point dataset have no topological component relating one point to another. For these reasons unstructured points are simple to represent but difficult to visualize. They are difficult to visualize because there is no inherent "structure" to which we can apply our library of visualization techniques. Beyond just displaying points (possibly colored with scalar value, or using oriented vector glyphs) none of the techniques discussed thus far can be used. Thus, to visualize unstructured points we have to build structure to which we can apply our visualization techniques.
There are several approaches available to build topological structure given a random set of points. One common approach samples unstructured points into an image dataset, and then visualizes the data using standard volume or surface-based rendering techniques. Another approach creates n-dimensional triangulations from the unstructured points, thereby creating topological structure. These and other common techniques are described in the following sections.
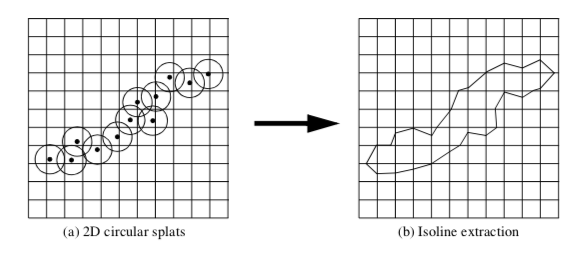
Splatting Techniques. Splatting techniques build topological structure by sampling unstructured points into a image dataset (Figure 9-36). The sampling is performed by creating special influence, or splatting, functions SF(x,y,z) that distribute the data value of each unstructured point over the surrounding region. To sample the unstructured points, each point is inserted into a image dataset SP, and the data values are distributed through SP using the splatting functions SF(x,y,z). Once the topological structure is built, any image-based visualization technique can be used (including volume rendering).
A common splatting function is a uniform Gaussian distribution centered at a point pi. The function is conveniently cast into the form
where s is a scale factor that multiplies the exponential, ff is the exponent scale factor f \geq 0, r is the distance between any point and the Gaussian center point (i.e., the splat point) r = \|p - p_ii|, and R is the radius of influence of the Gaussian, where r \leq R.
The Gaussian function (Figure 9-37(a)) becomes a circle in cross section in two dimensions (Figure 9-37(b)) and a sphere in three dimensions. Since the value of the function is maximum when r = 0, the maximum value is given by the scale factor s. The parameter f controls the rate of decay of the splat. Scalar values can be used to set the value of s, so that relatively large scalar values create bigger splats than smaller values.
Splats may be accumulated using the standard implicit modeling boolean operations (Equation 6-13, Equation 6-14, and Equation 6-15). That is, we may choose to form a union, intersection, or difference of the splats. The union and intersection operators are used most frequently.
Another interesting variation modifies the shape of the splat according to a vector quantity such as surface normal or vector data. Figure 9-37(c) shows an example where the splat shape is elongated in the direction parallel to a vector. Thus, if we have a set of points and normals, we can create a polygonal surface by combining splatting with isosurface extraction.
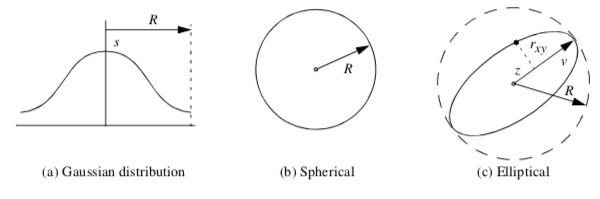
To generate oriented splats, we modify Equation 9-22 by introducing an eccentricity factor E and the vector \vec{v}.
where z and r_{xy} are computed from
The parameter z is the distance along the vector \vec{v}, and the parameter r_{xy} is the distance perpendicular to \vec{v} to the point p. The eccentricity factor controls the shape of the splat. A value E = 1 results in spherical splats, whereas E > 1 yields flattened splats and E < 1 yields elongated splats in the direction of the vector \vec{v}.
Figure 9-38(a) shows an elliptical splat with E = 10. (The splat surface is created by using isosurface extraction.) As expected, the splat is an ellipsoid. Figure 9-38(b) is an application of elliptical splatting used to reconstruct a surface from an unstructured set of points. The advantage of using an elliptical splat is that we can flatten the splat in the plane perpendicular to the point normal. This tends to bridge the space between the point samples. The surface itself is extracted using a standard isosurface extraction algorithm.
Interpolation Techniques. Interpolation techniques construct a function to smoothly interpolate a set of unstructured points. That is, given a set of n points p_i = (x_i, y_i, z_i) and function values F_i(p_i), a new function F(p) is created that interpolates the points p_i. Once the interpolation function is constructed, we can build topological structure from the unstructured points by sampling F(p) over an image dataset. We can then visualize the image data using any of the various techniques presented throughout the text.


Shepard's method is an inverse distance weighted interpolation technique [Wixom78]. The interpolation functions can be written
where F(p_i) = F_i. Shepard's method is easy to implement, but has the undesirable property that limits its usefulness for most practical applications. The interpolation functions generate a local "flat spot" at each point pi since the derivatives are zero
As a result, Shepard's method is overly constrained in the region around each point.
Shepard's method is an example of a basis function method. That is, the interpolation function F(p) consists of a sum of functions centered at each data point, pi. Other basis function methods have been developed as described by Nielson [Nielson91]. They vary in localization of the basis functions and the sophistication of the interpolation function. Localization of basis functions means that their effect is isolated to a small region. Examples of more sophisticated basis functions include quadratic polynomials and cubic splines. Please see the references for more information.
Triangulation techniques build topology directly from unstructured points. The points are triangulated to create a topological structure consisting of n-dimensional simplices that completely bound the points and linear combinations of the points (the so-called convex hull). The result of triangulation is a set of triangles (2D) or tetrahedra (3D), depending upon the dimension of the input data [Lawson86].
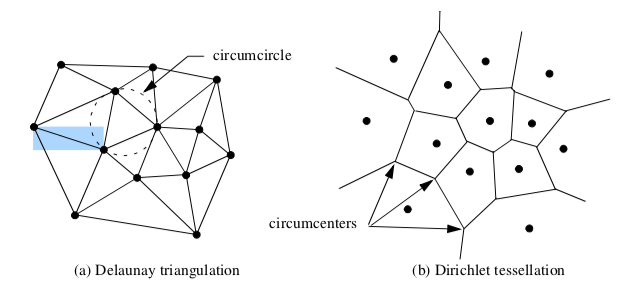
An n-dimensional triangulation of a point set P = (p_1, p_2, p_3, ..., p_n) is a collection of n-dimensional simplices whose defining points lie in P. The simplices do not intersect one another and share only boundary features such as edges or faces. The Delaunay triangulation is a particularly important form [Bowyer81] [Watson81]. It has the property that the circumsphere of any n-dimensional simplex contains no other points of P except the n+1 defining points of the simplex (Figure 9-39(a)).
The Delaunay triangulation has many interesting properties. In two dimensions, the Delaunay triangulation has been shown to be the optimal triangulation. That is, the minimum interior angle of a triangle in a Delaunay triangulation is greater than or equal to the minimum interior angle of any other possible triangulation. The Delaunay triangulation is the dual of the Dirichlet tessellation (Figure 9-39(b)), another important construction in computational geometry. The Dirichlet tessellation, also known as the Voronoi tessellation, is a tiling of space where each tile represents the space closest to a point pi. (The tiles are called Voronoi cells.) An n-dimensional Delaunay triangulation can be constructed from the Dirichlet tessellation by creating edges between Voronoi cells that share common n-1 boundaries (e.g., faces in 3D and edges in 2D). Conversely, the vertices of the Dirichlet tessellation are located at the circumcenters of the Delaunay circumcircles.
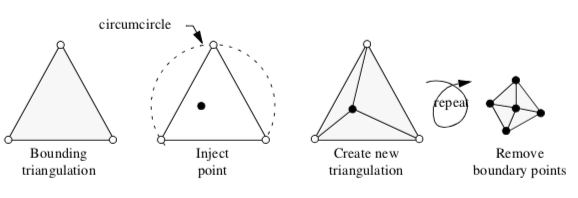
The Delaunay triangulation can be computed using a variety of techniques. We describe a particularly elegant technique introduced independently by Watson [Watson81] and Bowyer [Bowyer81] (Figure 9-40). The algorithm begins by constructing an initial Delaunay triangulation that strictly bounds the point set P, the so-called bounding triangulation. This bounding triangulation can be as simple as a single triangle (2D) or tetrahedron (3D). Then, each point of P is injected one by one into the current triangulation. If the injected point lies within the circumcircle of any simplex, then the simplex is deleted, leaving a "hole" in the triangulation. After deleting all simplices, the n-1 dimensional faces on the boundary of the hole, along with the injected point, are used to construct a modified triangulation. This is a Delaunay triangulation, and the process continues until all points are injected into the triangulation. The last step removes the simplices connecting the points forming the initial bounding triangulation to reveal the completed Delaunay triangulation.
This simplistic presentation of triangulation techniques has shown how to create topological structure from a set of unstructured points. We have ignored some difficult issues such as degeneracies and numerical problems. Degeneracies occur when points in a Delaunay triangulation lie in such a way that the triangulation is not unique. For example, the points lying at the vertices of a square, rectangle, or hexagon are degenerate because they can be triangulated in more than one way, where each triangulation is equivalent (in terms of Delaunay criterion) to the other. Numerical problems occur when we attempt to compute circumcenters, especially in higher-dimensional triangulations, or when simplices of poor aspect ratio are present.
Despite these problems, triangulation methods are a powerful tool for visualizing unstructured points. Once we convert the data into a triangulation (or in our terminology, an unstructured grid), we can directly visualize our data using standard unstructured grid techniques.
Hybrid Techniques. Recent work has focused on combining triangulation and basis function techniques for interpolating 2D bivariate data. The basic idea is as follows. A triangulation of P is constructed. Then an interpolating network of curves is defined over the edges of the triangulation. These curves are constructed with certain minimization properties of interpolating splines. Finally, the curve network is used to construct a series of triangular basis functions, or surface patches, that exhibit continuity in function value, and possibly higher order derivatives. (See [Nielson91] for more information.)
Multidimensional Visualization¶
The treatment of multidimensional datasets is an important data visualization issue. Each point in a dataset is described by an n-dimensional coordinate, where $n geq 3. Here we assume that each coordinate is an independent variable, and that we wish to visualize a single dependent variable. (Multi- dimensional visualization of vectors and tensors is an open research area.) An application of multidimensional data is financial visualization, where we might want to visualize return on investment as a function of interest rate, initial investment, investment period, and income, to name just a few possibilities.
There are two fundamental problems that we must address when applying multidimensional visualization. These are the problems of projection and understanding.
The problem of projection is that in using computer graphics we have two dimensions in which to present our data, or possibly three or four if we use specialized methods. Using 3D graphics we can give the illusion of three dimensions, or we can use stereo viewing techniques to achieve three dimensions. We can also use time as a fourth dimension by animating images. However, except for these limited situations, general n-dimensional data cannot be represented on a 2D computer screen.
The problem of understanding is that humans do not easily comprehend more than three dimensions, or possibly three dimensions plus time. Thus, even if we could create a technique to display data of many dimensions, the difficulty in understanding the data would impair the usefulness of the technique.
Most multidimensional visualization techniques work with some form of dimension mapping, where n dimensions are mapped to three dimensions and then displayed with 3D computer graphics techniques. The mapping is achieved by fixing all variables except three, and then applying the visualization techniques described throughout the text to the resulting data. For maximum benefit, the process of fixing independent variables, mapping to three dimensions, and then generating visualization must be interactive. This improves the effectiveness of the visualization process, allowing the user to build an internal model of the data by manipulating different parts of the data.
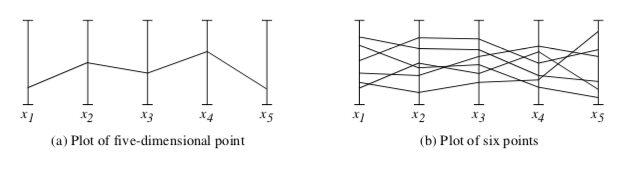
One novel approach to multidimensional visualization has been proposed by Inselberg and Dimsdale [Inselberg87]. This approach uses parallel coordinate systems. Instead of plotting points on orthogonal axes, the ith dimensional coordinate of each point is plotted along separate, parallel axes. This is shown in Figure 9-41 for a five-dimensional point. In parallel coordinate plots, points appear as lines. As a result, plots of n-dimensional points appear as sequences of line segments that may intersect or group to form complex fan patterns. In so doing, the human pattern recognition capability is engaged. Unfortunately, if the number of points becomes large, and the data is not strongly correlated, the resulting plots can become a solid mass of black, and any data trends are drowned in the visual display.
Another useful multivariable technique uses glyphs. This technique associates a portion of the glyph with each variable. Although glyphs cannot generally be designed for arbitrary n-dimensional data, in many applications we can create glyphs to convey the information we are interested in. Refer to "Glyphs" in Chapter 6 for more information about glyphs.
Texture Algorithms¶
Texturing is a common tool in computer graphics used to introduce detail without the high cost of graphics primitives. As we suggested in Chapter 7 - Advanced Computer Graphics, texture mapping can also be used to visualize data. We explore a few techniques in the following sections.
Texture Thresholding. We saw earlier how to threshold data based on scalar values (see "Thresholding" in this Chapter). We refer to this approach as geometric thresholding because structural components of a dataset (e.g., points and cells) are extracted based on data value. In contrast, we can use texture mapping techniques to achieve similar results. We call this technique texture thresholding.
Texture thresholding conceals features we do not want to see and accentuates features that we want to see. There are many variations on this theme. A feature can be concealed by making it transparent or translucent, by reducing its intensity, or using muted colors. A feature can be accentuated by making it opaque, increasing its intensity, or adding bright color. In the following paragraphs we describe a technique that combines intensity and transparency.
Texture thresholding requires two pieces of information: a texture map and an index into the map, or texture coordinate. In the simplest case we can devise a texture map that consists of two distinct regions as shown in Figure 9-42(a). The first region is alternatively referred to as "conceal," "off," or "outside." The second region is referred to as "accentuate," "on," or "inside." (These different labels are used depending upon the particular application.) With this texture map in hand we can texture threshold by computing an appropriate texture coordinate. Areas that we wish to accentuate are assigned a coordinate to map into the "accentuate" portion of the texture map. Areas that we want to conceal are assigned a coordinate to map into the "conceal" portion of the texture map.
One texture threshold technique uses transparency. We can conceal a region by setting its alpha opacity value to zero (transparent), and accentuate it by setting the alpha value to one (opaque). Thus, the texture map consists of two regions: a concealed region with \alpha = 0 and an accentuated region with \alpha = 1. Of course, the effect can be softened by using intermediate alpha values to create translucent images.
An extension of this technique introduces a third region into the texture map: a transition region (Figure 9-42(b)). The transition region is the region between the concealed and accentuated regions. We can use the transition region to draw a border around the accentuated region, further highlighting the region.
To construct the texture map we use intensity-alpha, or I\alpha values. The intensity modulates the underlying color, while the alpha value controls transparency (as described previously). In the accentuated region, the intensity and opacity values are set high. In the concealed region, the intensity value can be set to any value (if \alpha = 0) or to a lower value (if \alpha \ne 0).The transition reg ion can use various combinations of \alpha and intensity. A nice combination produces a black, opaque transition region (i.e., I = 0 and \alpha = 1 ).
To visualize information with the thresholding technique, we must map data to texture coordinates. As we saw previously, we can use scalar values in combination with a threshold specification to map data into the concealed, transition, and accentuated regions of the texture map. Figure 9-43a shows an example of texture thresholding applied to scalar data from a simulation of fluid flow. A scalar threshold sT is set to show only data with scalar value greater than or equal to sT.
Another useful texture thresholding application uses implicit functions to map point position to texture coordinate. This is similar in effect to geometric clipping (see "Clipping With Scalar Fields" in this Chapter). As we saw in "Implicit Functions" in Chapter 6, implicit functions naturally map a (x, y, z) coordinate value into three regions: F(x, y, z) < 0, F(x, y, z) = 0, and F(x, y, z) > 0 ; or equivalently, the concealed, transition, and accentuated regions of the texture map. Using boolean combinations of implicit functions, we can create complex cuts of our data as illustrated in Figure 9-43b. This figure shows two nested spheres. The outer sphere is cut by a boolean combination of two planes to show the inner sphere.
Boolean Textures. Texture thresholding can be extended into higher dimensions. That is, 2D or 3D texture coordinates can be used to map two or three data variables into a texture map. One such technique is boolean textures, a method to clip geometry using a 2D texture map and two implicit functions [Lorensen93].
Boolean textures extend texture thresholding for geometric clipping from 1D to 2D. Instead of using a single implicit function to label regions "in" or "out", two implicit functions are used. This results in four different regions corresponding to all possible combinations of "in" and "out."

The boolean texture map is modified to reflect this as shown in Figure 9-44. As with 1D texture thresholding, transition regions can be created to separate the four regions.
The boolean texture map can be created with combinations of intensity and transparency values to achieve a variety of effects. By combining the four combinations of in/out (i.e., four regions of Figure 9-44) with the two combinations of "conceal" and "accentuate," sixteen different boolean textures are possible. Figure 9-45a illustrates these combinations expressed as boolean combinations of two implicit functions A and B. The "inside" of the implicit functions is indicated with subscript i, while the outside is indicated with subscript o. The boolean expressions indicate the regions that we wish to conceal, as shown by open circles. The darkened circles are the regions that are accentuated. We can see in Figure 9-45b the effects of applying these different boolean textures to a sphere. The implicit functions in this figure are two elliptical cylinders sharing a common axis, and rotated 90 degrees from one another. In addition, transition regions have been defined with I = 0 to generate the dark cut edges shown. All 16 spheres share the same texture coordinates; only the texture map changes.
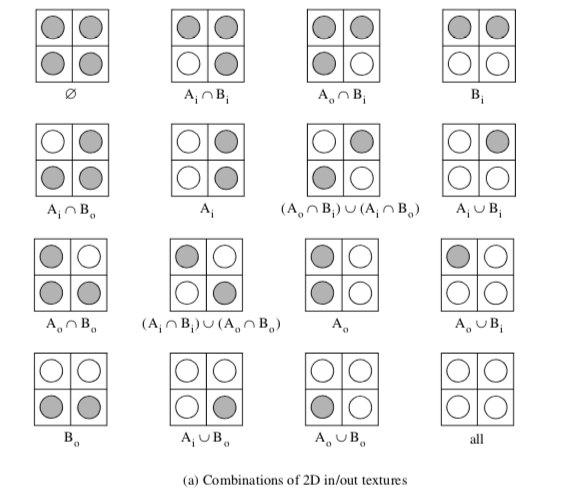
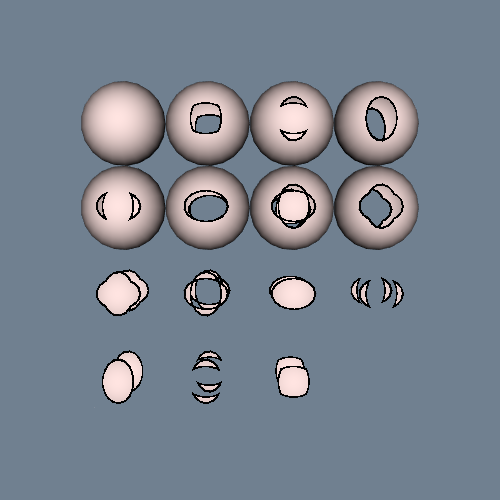
Texture Animation. Time-based animation techniques can illustrate motion or temporal data variations. This process often requires relatively large amounts of computer resource to read, process, and display the data. Thus, techniques to reduce computer resources are desirable when animating data.
Texture mapping can be used to animate certain types of data. In these techniques, the data is not regenerated frame by frame, instead a time-varying texture map is used to change the visual appearance of the data. An example of this approach is texture animation of vector fields [Yamrom95].
As we saw in "Hedgehogs and Oriented Glyphs" in Chapter 6, vector fields can be represented as oriented and scaled lines. Texture animation can transform this static representational scheme into a dynamic representation. The key is to construct a series of 1D texture maps that when applied rapidly in sequence create the illusion of motion. Figure 9-46(a) shows a series of sixteen such texture maps. The maps consist of intensity-alpha (I \alpha ) values, A portion of the texture map is set fully opaque with full intensity (I = 1, \alpha = 1 ). This is shown as the "dark" pattern in Figure 9-46(a). The remainder of the map is set fully transparent with arbitrary intensity ( I = 1, \alpha = 0 ) shown as the "white" portion. As is evidenced by the figure, the sequence of 16 texture maps scanned top to bottom generate the appearance of motion from left to right. Notice also how the texture maps are designed to wrap around to form a continuous pattern.
Along with the 1D texture map, the texture coordinate s must also be generated - on a line this is straightforward. The line origin receives texture coordinate s = 0, while the line terminus receives texture coordinate value s = 1. Any intermediate points (if the vector is a polyline) are parameterized in monotonic fashion in the interval (0,1). Texture coordinates need only be generated once. Only the texture map is varied to generate the vector animation.
Other effects are possible by modifying the texture map. Figure 9-46(b) shows a texture map with a repeating sequence of opaque/transparent regions. In each opaque region the intensity is gradually reduced from left to right. The result is that this tends to "feather" the appearance of the vector motion. The resulting image is more pleasing to the eye.
9.5 Putting It All Together¶
With the conclusion of this chapter we have provided an overview of the basics of data visualization. In this section we show you how to use some of the advanced algorithms as implemented in the Visualization Toolkit.
Dividing Cubes / Point Generation¶
Dividing cubes is implemented in VTK with the class vtkDividingCubes. It has been specialized to operate with image datasets. Besides specifying the contour value, you must specify a separation distance between points (using the method SetDistance()). If you desire a solid appearance, pick a distance that is less than or equal to display resolution.
The separation distance controls the accuracy of point generation. It is possible to generate points that appear to form a solid surface when rendered, but are not accurately located on the contour surface. Although this usually is not an issue when viewing contour surfaces, if the accuracy of the point positions is important, the distance value must be set smaller. However, this can result in huge numbers of points. To reduce the number of points, you can use the SetIncrement() method, which specifies that every nth point is to be generated. Using this approach, you can obtain good accuracy and control the total number of points. An example where point positions are important is when the points are used to locate glyphs or as seed points for streamline generation.
The Visualization Toolkit provides other point generation techniques. The source object vtkPointSource generates a user-specified number of points within a spherical region. The point positions are random within the sphere. (Note that there is a natural tendency for higher point density near the center of the sphere because the points are randomly generated along the radius and spherical angles \phi and \theta.)
Figure 9-47 is an example use of vtkPointSource to generate streamlines. The dataset is a structured grid of dimensions 21 \times 20 \times 20 with flow velocity and a scalar pressure field. The dataset is a CFD simulation of flow in a small office. As this picture shows, there are a couple of bookcases, desks, a window, and an inlet and outlet for the ventilation system. On one of the desks is a small, intense heat source (e.g., a cigarette). In the left image 25 streamlines are started near the inlet using a vtkPointSource point generator. The second image shows what happens when we move the point source slightly to the left. By adjusting a single parameter (e.g., the center of the point source) it is possible to quickly explore our simulation data.
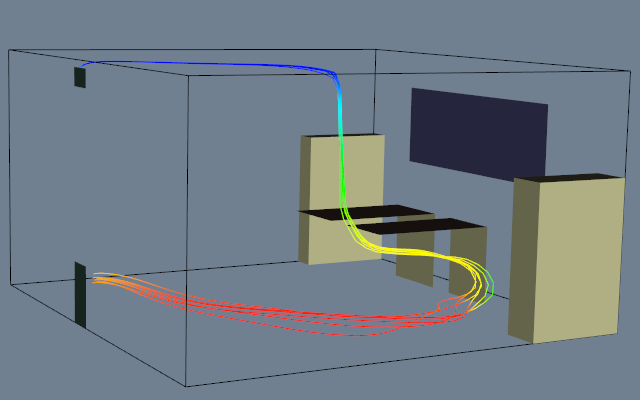
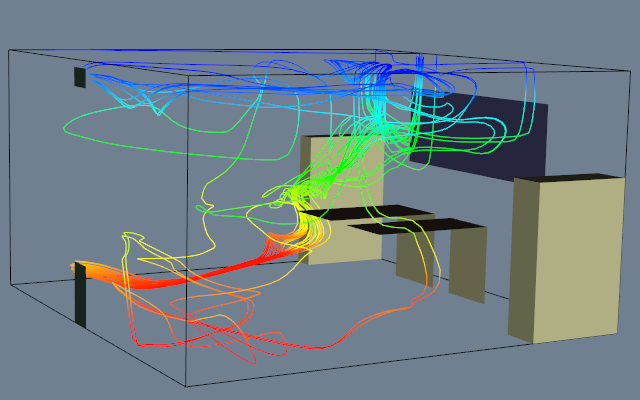
Another convenient object for point generation is the class vtkEdgePoints. vtkEdgePoints generates points on an isosurface. The points are generated by locating cell edges whose points are both above and below the isosurface value. Linear interpolation is used to generate the point. Since vtkEdgePoints operates on any cell type, this filter's input type is any dataset type (e.g.,vtkDataSet). Unlike vtkDividingCubes this filter will not typically generate dense point clouds that appear solid.
Clipping with Scalar Fields¶
Clipping is implemented in vtkClipPolyData. Each polygonal data primitive implements the operation in its Clip() method using cases tables derived in a manner similar to that of triangles described here.. vtkClipPolyData has methods to control whether an implicit function provides the scalar data or whether the dataset's scalar data will be used. ComputeScalarDataOn() uses the implicit function and ComputeScalarDataOff() uses the dataset's scalar data. Two output polygonal datasets are produced. These are accessed with GetOutput() and GetClippedOutput() methods. GetOutput() returns the polygonal data that is "inside' the clipping region while GetClippedOutput() returns polygonal data that is "outside" the region. (Note that GenerateClippedOutputOn() must be enabled if you are to get the clipped output.) The meaning of inside and outside can be reversed using the InsideOutOn() method. Figure 9-48 shows a plane of quadrilaterals clipped with a boolean implicit function.

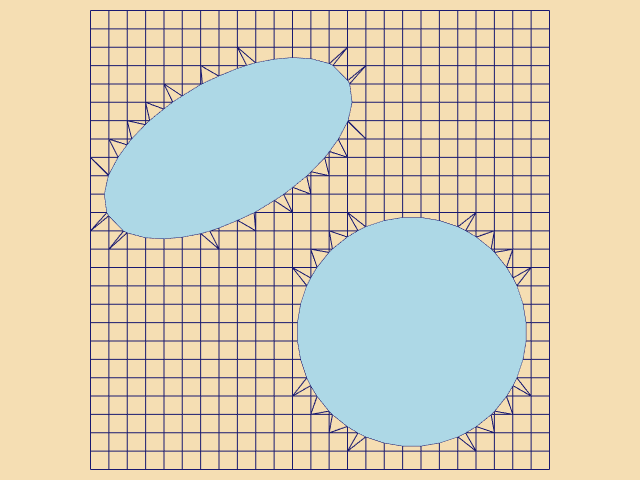
Until recently, VTK supported clipping only for polygonal data cell types (vertices, polyvertices, line, polylines, polygons and triangle strips). Recent additions since VTK version 4.0 support clipping of 3D cells using an ordered Delaunay triangulation approach.
Swept Volumes and Surfaces¶
Swept surfaces can be applied in two interesting ways. First, they can be used as a modelling tool to create unusual shapes and forms. In this sense, swept surfaces are an advanced implicit modelling technique. Second, swept surfaces can be used to statically represent object motion. This is an important visualization technique in itself and has many important applications. One of these applications is design for maintainability.
When a complex mechanical system like a car engine is designed, it is important to design proper access to critical engine components. These components, like spark plugs, require higher levels of service and maintenance. It is important that these components can be easily reached by a mechanic. We've read horror stories of how it is necessary to remove an engine to change a spark plug. Insuring ready access to critical engine parts prevents situations like this from occurring.
Swept surface can assist in the design of part access. We simply define a path to remove the part (early in the design process), and then generate a swept surface. This surface (sometimes referred to as a maintenance access solid or MAS) is then placed back into the CAD system. From this point on, the design of surrounding components such as fuel lines or wiring harnesses must avoid the MAS. As long as the MAS is not violated, the part can be removed. If the MAS is violated, a reevaluation of the removal path or redesign of the part or surrounding components is necessary.
Figure 9-49 shows how to create a swept surface from a simple geometric representation. The geometry is simply a line-stroked VTK. The next step is to define a motion path. This path is defined by creating a list of transformation matrices. Linear interpolation is used to generate intermediate points along the path if necessary.
In Figure 9-49 we also see the basic procedure to construct the swept surface. First, we must construct an implicit representation of the part by using vtkImplictModeller. This is then provided as input to vtkSweptSurface. It is important that the resolution of the implicit model is greater than or equal to that of vtkSweptSurface. This will minimize errors when we construct the surface. A bounding box surrounding the part and its motion can be defined, or it will be computed automatically. For proper results, this box must strictly contain the part as its moves. We also can set the number of interpolation steps, or allow this to be computed automatically as well. In the figure, we have chosen a small number to better illustrate the stepping of the algorithm.
Once vtkSweptSurface executes, we extract the swept surface using an isosurfacing algorithm. The isosurface value is an offset distance; thus we can create surfaces that take into account geometry tolerance. (This is particularly important if we are designing mechanical systems.) The implementation of the implicit modeller in VTK uses a positive distance function; so the isosurface value should always be positive. To create swept surfaces of zero and negative value requires a modification to the implicit modeller.

Multidimensional Visualization¶
An important characteristic of multidimensional datasets is that they cannot be categorized according to any of the types defined in the Visualization Toolkit. This implies that source objects interfacing with multidimensional data are responsible for converting the data they interface with into one of the types defined in VTK. This can be a difficult process, requiring you to write interface code.
Other visualization systems treat this problem differently. In these systems a dataset type is defined that can represent multidimensional data. This dataset type is essentially an n-dimensional matrix. Additional filters are defined that allow the user to extract pieces of the dataset and assemble them into a more conventional dataset type, such as a volume or structured grid. After mapping the data from multidimensional form to conventional form, standard visualization techniques can be applied. (Future implementations of VTK may include this functionality. At the current time you must map multidimensional data into a known VTK form.)
To demonstrate these ideas we will refer to Figure 9-50. This is an example of multidimensional financial data. The data reflects parameters associated with monetary loans. In the file financial.txt there are six different variables: TIME_LATE, MONTHLY_PAYMENT, UNPAID_PRINCIPLE, LOAN_AMOUNT, INTEREST_RATE, and MONTHLY_INCOME. (Note: this is simulated data, don't make financial decisions based upon this!)
We will use Gaussian splatting to visualize this data (see "Splatting Techniques" in this Chapter).

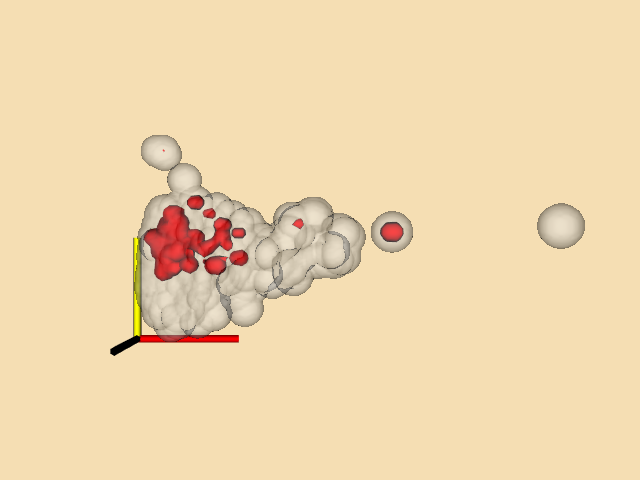
Our first step is to choose dependent and independent variables. This choice is essentially a mapping from multidimensional data into an unstructured point dataset. In this example we will choose MONTHLY_PAYMENT, INTEREST_RATE, and LOAN_AMOUNT as our (x, y, z) point coordinates, and TIME_LATE as a scalar value. This maps four of six variables. For now we will ignore the other two variables.
We use vtkGaussianSplatter to perform the splatting operation (i.e., conversion from unstructured points to volume dataset). This is followed by an isosurface extraction. We splat the data two times. The first time we splat the entire population. This is to show context and appears as gray/ wireframe in the figure. The second time we splat the data and scale it by the value of TIME_LATE. As a result, only payments that are late contribute to the second isosurface.
The results of this visualization are interesting. First, we see that there is a strong correlation between the two independent variables MONTHLY_PAYMENT and LOAN_AMOUNT. (This is more evident when viewing the data interactively.) We see that the data falls roughly on a plane at a 45 degree angle between these two axes. With a little reflection this is evident: the monthly payment is strongly a function of loan amount (as well as interest rate and payment period). Second, we see that there is a clustering of delinquent accounts within the total population. The cluster tends to grow with larger interest rates and shrink with smaller monthly payments and loan amounts. Although the relationship with interest rate is expected, the clustering towards smaller monthly payments is not. Thus our visualization has provided a clue into the data. Further exploration may reveal the reason(s), or we may perform additional data analysis and acquisition to understand the phenomena.
One important note about multidimensional visualization. Because we tend to combine variables in odd ways (e.g., the use of MONTHLY_PAYMENT, INTEREST_RATE, and LOAN_AMOUNT as (x, y, z) coordinates), normalization of the data is usually required. To normalize data we simply adjust data values to lie between (0,1). Otherwise our data can be badly skewed and result in poor visualizations.
Connectivity¶
Many useful visualization algorithms often borrow from other fields. Topological connectivity analysis is one such technique. This technique is best categorized as a method in computational geometry, but serves many useful purposes in computer graphics and visualization.
To illustrate the application of connectivity analysis, we will use an MRI dataset generated by Janet MacFall at the Center for In Vivo Microscopy at Duke University. The dataset is a volume of dimensions 2563 and is included on the CD-ROM. The data is of the root system of a small pine tree. Using the class vtkSliceCubes, an implementation of marching cubes for large volumes, we generate an initial isosurface represented by 351,118 triangles. (We have placed the file pine_root.tri on CD-ROM. This is a faster way of manipulating this data. If you have a large enough computer you can process the volume directly with vtkVolume16Reader and vtkMarchingCubes.)



The vtkConnectivityFilter is a general filter taking datasets as input, and generating an unstructured grid as output. It functions by extracting cells that are connected at points (i.e., share common points). In this example the single largest surface is extracted. It is also possible to specify cell ids and point ids and extract surfaces connected to these.
Decimation¶
Decimation is a 3D data compression technique for surfaces represented as triangle meshes. We use it most often to improve rendering interactive response for large models.
Figure 9-52 shows the application of decimation to the data from the pine root example. The original model of 351,118 triangles is reduced to 81,111 triangles using a combination of decimation and connectivity. The decimation parameters are fairly conservative. Here we see a reduction of approximately 55 percent.

The most common parameters to adjust in the vtkDecimate filter are the TargetReduction, InitialError, ErrorIncrement, MaximumIterations, and InitialFeatureAngle. TargetReduction specifies the compression factor (numbers closer to one represent higher compression). Because of topological, decimation criterion, aspect ratio, and feature angle constraints this reduction may not be realized (i.e., TargetReduction is a desired goal, not a guaranteed output). The InitialError and ErrorIncrement control the decimation criterion. As the filter starts, the decimation criterion is set to InitialError. Then, for each iteration the decimation criterion is incremented by ErrorIncrement. The algorithm terminates when either the target reduction is achieved, or the number of iterations reaches MaximumIterations. The InitialFeatureAngle is used to compute feature edges. Smaller angles force the algorithm to retain more surface detail.
Other important parameters are the AspectRatio and MaximumSubIterations. AspectRatio controls the triangulation process. All triangles must satisfy this criterion or the vertex will not be deleted during decimation. A sub-iteration is an iteration where the decimation criterion is not incremented. This can be used to coalesce triangles during rapid rates of decimation. MaximumSubIterations controls the number of sub-iterations. This parameter is typically set to two.
Texture Clipping¶
Texture mapping is a powerful visualization technique. Besides adding detail to images with minimal effort, we can perform important viewing and modelling operations. One of these operations is clipping data to view internal structure.
Figure 9-53 is an example of texture clipping using a transparent texture map. The motor show consists of five complex parts, some of which are hidden by the outer casing. To see the inside of the motor, we define an implicit clipping function. This function is simply the intersection of two planes to form a clipping "corner." The object vtkImplicitTextureCoords is used in combination with this implicit function to generate texture coordinates. These objects are then rendered with the appropriate texture map and the internal parts of the motor can be seen.
The texture map consists of three regions (as described previously in the chapter). The concealed region is transparent. The transition region is opaque but with a black (zero intensity) color. The highlighted region is full intensity and opaque. As can be seen from Figure 9-53, the boundaries appear as black borders giving a nice visual effect.
The importance of texture techniques is that we can change the appearance of objects and even perform modelling operations like clipping with little effort. We need only change the texture map. This process is much faster relative to the alternative approach of geometric modelling. Also, hardware support of texture is becoming common. Thus the rendering rate remains high despite the apparent increase in visual complexity.
Delaunay Triangulation¶
Delaunay triangulation is used to construct topology from unstructured point data. In two dimensions we generate triangles (i.e., an unstructured grid or polygonal dataset) while in three dimensions we generate tetrahedra (i.e., an unstructured grid). Typical examples of image data include points measured in space, or a dimensional subset of multidimensional data.
In the example of Figure 9-54 we show how to create a 2D Delaunay triangulation from a field of points. The points are created by generating random x and y coordinate values in the interval [0, 1], and setting the z-value to a constant value (i.e., the points lie in an x-y plane). The points are then triangulated, and tubes and sphere glyphs are used to highlight the resulting points and edges of the triangulation.
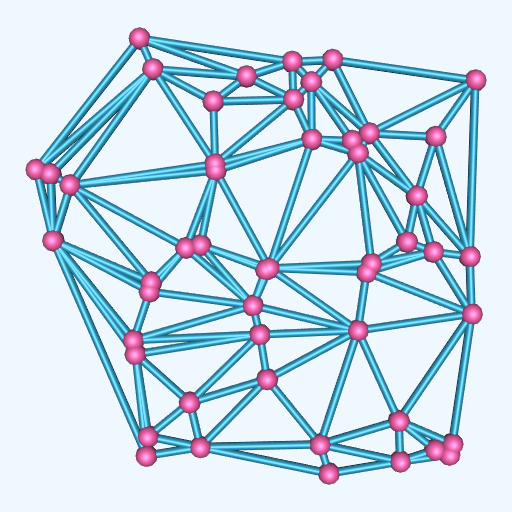
One important concern regarding Delaunay triangulations is that the process is numerically sensitive. Creating triangles with poor aspect ratio (e.g., slivers) can cause the algorithm to break down. If you have a large number of points to triangulate, you may want to consider randomizing the point order. This approach tends to generate triangles with better aspect ratio and give better results. You may also want to consider other implementations of Delaunay triangulation that are more numerically robust. See [Edelsbrunner94] for an example.
9.6 Chapter Summary¶
Dividing cubes is a scalar contouring operation that generates points rather than surface primitives such as lines or polygons. Dense point clouds appear solid because of the limited resolution of computer images.
Vector fields have a complex structure. This structure can be visualized using streamribbons, streamsurfaces, and streampolygons. The topology of a vector field can be characterized by connecting critical points with streamlines.
Tensor fields consist of three orthogonal vector fields. The vector fields are the major, medium, and minor eigenvectors of the tensor field. Hyperstreamlines can be used to visualize tensor fields.
Dataset topology operations generate triangle strips, extract connected surfaces, and compute surface normals. Decimation is a polygon reduction algorithm that reduces the number of triangles in a triangle mesh. Implicit modelling techniques can be used to construct swept surfaces and volumes. Unstructured points are easy to represent but difficult to visualize. Splatting, interpolation, and triangulation techniques are available to construct structure for unstructured points. Multivariate visualization is required for data of dimension four and higher. Data must be mapped to three dimensions before standard visualization techniques can be used. Parallel coordinates techniques are also available to visualize multivariate data.
Modelling algorithms extract geometric structure from data, reduce the complexity of the data or create geometry. Spatial extraction selects dataset structure and associated data attributes lying within a specified region in space. Subsampling reduces data by selecting every nth data point. A related technique, data masking, selects every nth cell. Subsets of a dataset can also be selected using thresholding, which selects cells or points that lie within a range of scalar values. Probing resamples data at a set of points. The probe produces a dataset that has the topology of the probe with data values from the probed dataset. Generating triangle strips can reduce storage requirements and improve rendering speeds on some systems. If a dataset has multiple disjoint structures, a connectivity algorithm can uniquely identify the separate structures. For polygonal data that does not have vertex normals defined, normal generation algorithms can compute these values that are suitable for interpolation by Gouraud or Phong shading. Decimation, another data reduction technique, removes triangles in "flat" regions and fills the resulting gaps with new triangles. Unstructured points present a challenge because the data does not have topology. Splatting represents each point in the data with a uniform sampling and accumulates these splats using implicit modelling techniques. Triangulation techniques build topology directly from the unstructured points.
Multidimensional visualization techniques focus on data that has many scalar data values for each point. Parallel coordinates is an interesting approach that plots the scalar values for a data point along a parallel axis. The observer looks for trends and relationships between the lines that represent each point's data.
Texture algorithms use texture coordinates and texture maps to select or highlight portions of a dataset. Texture thresholding assigns texture coordinates based on a scalar value. The scalar value and texture map determine how a cell or portion of a cell is rendered. Boolean textures extend this concept to 2D and 3D. Careful design of a boolean texture map permits the "clipping" of geometry with combinations of implicit surfaces. Texture can also be used to animate vector fields.
9.7 Bibliographic Notes¶
Dividing cubes is an interesting algorithm because of the possibilities it suggests [Cline88]. Point primitives are extremely simple to render and manipulate. This simplicity can be used to advantage to build accelerated graphics boards, perform 3D editing, or build parallel visualization algorithms.
Many plotting and visualization systems use carpet plots extensively. Carpet plots are relatively easy to represent and render. Often 2D plotting techniques are used (i.e., lighting and perspective effects ignored). Check [Wang90] for additional information on rendering carpet plots.
In recent years a number of powerful vector visualization techniques have emerged. These techniques include streamsurfaces [Hultquist92], streampolygons [Schroeder91], vector field topology [Helman91] [Globus91], streamballs [Brill94], and vorticity visualization [Banks94]. The streamballs technique is a recent technique that combines techniques from implicit modeling. You may also wish to see references [Crawfis92] [vanWijk93] and [Max94]. These describe volume rendering and other advanced techniques for vector visualization, topics not well covered in this text.
Some abstract yet beautiful visualization images are due to Delmarcelle and Hesselink [Delmarcelle93]. Their rendering of hyperstreamlines reflect the underlying beauty and complexity of tensor fields.
Polygon reduction is a relatively new field of study. SIGGRAPH '92 marked a flurry of interest with the publication of two papers on this topic [Schroeder92a] [Turk92]. Since then a number of valuable techniques have been published. One of the best techniques, in terms of quality of results, is given by [Hoppe93], although it is limited in time and space because it is based on formal optimization techniques. Other interesting methods include [Hinker93] and [Rossignac93]. A promising area of research is multiresolution analysis, where wavelet decomposition is used to build multiple levels of detail in a model [Eck95]. The most recent work in this field stresses progressive transmission of 3D triangle meshes [Hoppe96], improved error measures [Garland97], and algorithms that modify mesh topology [Popovic97] [Schroeder97]. Most recently an extensive book on the technology is available including specialized methods for terrain simplification [Luebke02].
Triangle strip generation is an effective technique for achieving dramatic improvements in rendering speed and reductions in data handling. The reference by [Evans96] describes other triangle strip generation algorithms as well as presenting some of the most effective tvechniques to date.
The use of texture for visualization is relatively unexploited. This has been due in part to lack of texture support in most graphics software and hardware. This is now changing, as more vendors support texture and software systems (such as OpenGL) that provide an API for texture. Important references here include the boolean textures [Lorensen93] and surface convolution techniques [Cabral93] [Stalling95].
Unstructured or unorganized point visualization is likely to play a prominent role in visualization as the field matures and more complex data is encountered. Nielson et al. have presented important work in this field [Nielson91].
Multidimensional visualization is another important focus of visualization research [Bergeron89] [Mihalisin90]. Much real-world data is both unstructured and multidimensional. This includes financial databases, marketing statistics, and multidimensional optimization. Addressing this type of data is important to achieve future advances in understanding and application. Feiner [Feiner90] has presented a simple projection method combined with virtual reality techniques. [Inselberg87] has introduced parallel coordinates. These techniques have been shown to be powerful for many types of visual analysis.
9.8 References¶
[Banks94] D. C. Banks and B. A. Singer. "Vortex Tubes in Turbulent Flows: Identification, Representation, Reconstruction." In Proceedings of Visualization '94. pp. 132-139, IEEE Computer Society Press, Los Alamitos, CA, 1994.
[Bergeron89] R. D. Bergeron and G. Grinstein. "A Reference Model for the Visualization of Multidimensional Data.' In Proceedings Eurographics "89. pp. 393-399, North Holland, Amsterdam, 1989.
[Bowyer81] A. Bowyer. "Computing Dirichlet Tessellations.' The Computer Journal. 24(2):162-166, 1981.
[Brill94] M. Brill, H. Hagen, H-C. Rodrian, W. Djatschin, S. V. Klimenko. "Streamball Techniques for Flow Visualization." In Proceedings of Visualization '94. pp. 225-231, IEEE Computer Society Press, Los Alamitos, CA, 1994.
[Cabral93] B. Cabral and L. Leedom. "Imaging Vector Fields Using Line Integral Convolution." In Proceedings of SIGGRAPH '93, pp. 263-270, Addison-Wesley, Reading, MA, 1993.
[Cline88] H. E. Cline, W. E. Lorensen, S. Ludke, C. R. Crawford, and B. C. Teeter, "Two Algorithms for the Three-Dimensional Construction of Tomograms." Medical Physics. 15(3):320-327, June 1988.
[Crawfis92] R, Crawfis and N. Max. "Direct Volume Visualization of Three Dimensional Vector Fields." In Proceedings 1992 Workshop on Volume Visualization. pp. 55-60, ACM Siggraph, New York, 1992.
[Delmarcelle93] T. Delmarcelle and L. Hesselink. "Visualizing Second-Order Tensor Fields with Hyperstreamlines." IEEE Computer Graphics and Applications. 13(4):25-33, 1993.
[Eck95] M. Eck, T. DeRose, T. Duchamp, H. Hoppe, M. Lounsbery, W. Stuetzle. "Multiresolution Analysis of Arbitrary Meshes." In Proceedings SIGGRAPH '95. pp. 173-182, Addison-Wesley, Reading, MA, August 1995.
[Edelsbrunner94] H. Edelsbrunner and E. P. Mucke. "Three-dimensional alpha shapes." ACM Transactions on Graphics. 13:43-72, 1994.
[Evans96] F. Evans, S. Skiena, A. Varshney. "Optimizing Triangle Strips for Fast Rendering." In Proceedings of Visualization '96. pp. 319-326, IEEE Computer Society Press, Los Alamitos, CA, 1996.
[Feiner90] S. Feiner and C. Beshers. "Worlds within Worlds: Metaphors for Exploring n-Dimensional Virtual Worlds." In Proceedings UIST '90 (ACM Symp. on User Interface Software). pp. 76-83, October, 1990.
[Garland97] M. Garland and P. Heckbert. "Surface Simplification Using Quadric Error Metrics." In Proceedings SIGGRAPH '97. pp. 209-216, The Association for Computing Machinery, New York, August 1997.
[Globus91] A. Globus, C. Levit, and T. Lasinski. "A Tool for Visualizing the Topology of Three-Dimensional Vector Fields." In Proceedings of Visualization '91. pp. 33-40, IEEE Computer Society Press, Los Alamitos, CA, 1991.
[He96] T. He, L. Hong, A. Varshney, S. Wang. "Controlled Topology Simplification." IEEE Transactions on Visualization and Computer Graphics. 2(2):171-184, June 1996.
[Helman91] J. L. Helman and L. Hesselink. "Visualization of Vector Field Topology in Fluid Flows.' IEEE Computer Graphics and Applications. 11(3):36-46, 1991.
[Hinker93] P. Hinker and C. Hansen. "Geometric Optimization." In Proceedings of Visualization '93. pp. 189-195, IEEE Computer Society Press, Los Alamitos, CA, October 1993.
[Hoppe93] H. Hoppe, T. DeRose, T. Duchamp, J. McDonald, W. Stuetzle. "Mesh Optimization." In Proceedings of SIGGRAPH '93. pp. 19-26, August 1993.
[Hoppe96] H. Hoppe. "Progressive Meshes." In Proceedings SIGGRAPH '96. pp. 96-108, The Association for Computing Machinery, New York, August 1996.
[Hultquist92] J. P. M. Hultquist. "Constructing Stream Surfaces in Steady 3-D Vector Fields." In Proceedings of Visualization '92. pp. 171-178, IEEE Computer Society Press, Los Alamitos, CA, 1992.
[Inselberg87] A. Inselberg and B. Dimsdale. "Parallel Coordinates for Visualizing Multi-Dimensional Geometry." In Computer Graphics 1987 (Proceedings of CG International '87). pp. 25-44, SpringerVerlag, 1987.
[Lawson86] C. L. Lawson. "Properties of n-Dimensional Triangulations." Computer-Aided Geometric Design. 3:231-246, 1986.
[Lorensen93] W. Lorensen. "Geometric Clipping with Boolean Textures." in Proceedings of Visualization '93. pp. 268-274, IEEE Computer Society Press, Los Alamitos, CA, Press, October 1993.
[Luebke02] D. Luebke, M. Reddy, J. Cohen, A. Varshney, B. Watson, R. Huebner. Level of Detail for 3D Graphics. Morgan Kaufmann 2002. ISBN 1-55860-838-9.
[Max94] N. Max, R. Crawfis, C. Grant. "Visualizing 3D Vector Fields Near Contour Surfaces." In Proceedings of Visualization '94. pp. 248-255, IEEE Computer Society Press, Los Alamitos, CA, 1994.
[Mihalisin90] T. Mihalisin, E. Gawlinski, J. Timlin, and J. Schwegler. "Visualizing a Scalar Field on an n-Dimensional Lattice." In Proceedings of Visualization '90. pp. 255-262, IEEE Computer Society Press, Los Alamitos, CA, October 1990.
[Nielson91] G. M. Nielson, T. A. Foley, B. Hamann, D. Lane. "Visualizing and Modeling Scattered Multivariate Data." IEEE Computer Graphics and Applications. 11(3):47-55, 1991.
[Popovic97] J. Popovic and H. Hoppe. "Progressive Simplicial Complexes." In Proceedings SIGGRAPH '97. pp. 217-224, The Association. for Computing Machinery, New York, August 1997.
[Rossignac93] J. Rossignac and P. Borrel. "Multi-Resolution 3D Approximations for Rendering Complex Scenes." In Modeling in Computer Graphics: Methods and Applications. B. Falcidieno and T. Kunii, eds., pp. 455-465, Springer-Verlag Berlin, 1993.
[Schroeder91] W. Schroeder, C. Volpe, and W. Lorensen. "The Stream Polygon: A Technique for 3D Vector Field Visualization." In Proceedings of Visualization '91. pp. 126-132, IEEE Computer Society Press, Los Alamitos, CA, October 1991.
[Schroeder92a] W. Schroeder, J. Zarge, and W. Lorensen. "Decimation of Triangle Meshes." Computer Graphics (SIGGRAPH "92). 26(2):65-70, August 1992.
[Schroeder92b] W. Schroeder, W. Lorensen, G. Montanaro, and C. Volpe. "Visage: An Object-Oriented Scientific Visualization System.' In Proceedings of Visualization "92. pp. 219-226, IEEE Computer Society Press, Los Alamitos, CA, October 1992.
[Schroeder94] W. Schroeder, W. Lorensen, and S. Linthicum, "Implicit Modeling of Swept Surfaces and Volumes." In Proceedings of Visualization '94. pp. 40-45, IEEE Computer Society Press, Los Alamitos, CA, October 1994.
[Schroeder97] W. Schroeder. "A Topology Modifying Progressive Decimation Algorithm." In Proceedings of Visualization '97. IEEE Computer Society Press, Los Alamitos, CA, October 1997.
[Stalling95] D. Stalling and H-C. Hege. "Fast and Independent Line Integral Convolution." In Proceedings of SIGGRAPH '95. pp. 249-256, Addison-Wesley, Reading, MA, 1995.
[Turk92] G. Turk. "Re-Tiling of Polygonal Surfaces." Computer Graphics (SIGGRAPH '92). 26(2):55-64, July 1992.
[vanWijk93] J. J. van Wijk. "Flow Visualization with Surface Particles." IEEE Computer Graphics and Applications. 13(4):18-24, 1993.
[Wang90] S-L C. Wang and J. Staudhammer. "Visibility Determination on Projected Grid Surfaces." IEEE Computer Graphics and Applications. 10(4):36-43, 1990.
[Watson81] D. F. Watson. "Computing the n-Dimensional Delaunay Tessellation with Application to Voronoi Polytopes." The Computer Journal. 24(2):167-172, 1981.
[Wixom78] J. Wixom and W. J. Gordon. "On Shepard's Method of Metric Interpolation to Scattered Bivariate and Multivariate Data." Math. Comp. 32:253-264, 1978.
[Yamrom95] B. Yamrom and K. M. Martin. "Vector Field Animation with Texture Maps." IEEE Computer Graphics and Applications. 15(2):22-24, 1995.
9.9 Exercises¶
9.1 Describe an approach to adapt dividing cubes to other 3D cell types. Can your method be adapted to 1D and 2D cells?
9.2 Discuss the advantages and disadvantages of representing surfaces with points versus polygons.
9.3 Streamribbons can be constructed by either i) connecting two adjacent streamlines with a surface, or ii) placing a ribbon on the streamline and orienting the surface according to streamwise vorticity vector. Discuss the differences in the resulting visualization.
9.4 Write the following programs to visualize velocity flow in the combustor. a) Use vtkProbeFilter and vtkHedgeHog.
b) Use vtkProbeFilter and vtkStreamLine.
c) Use vtkProbeFilter and vtkWarpVector.
d) Use vtkProbeFilter and vtkVectorNorm.
e) Use vtkProbeFilter and vtkVectorDot.
9.5 Describe a method to extract geometry using an arbitrary dataset. (That is, extract geometry that lies within the culling dataset.) (Hint: how would you evaluate in/out of points?)
9.6 The filter vtkPolyDataNormals is often used in combination with the filters vtkSmoothPolyData and vtkContourFilter to generate smooth isosurfaces.
a) Write a class to combine these three filters into one filter. Can you eliminate intermediate storage?
b) How much error does vtkSmoothPolyData introduce into the isosurface? Can you think of a way to limit the error?
c) What is the difference between the surface normals created by vtkMarchingCubes and vtkPolyDataNormals?
9.7 Assume that we have a database consisting of interest rate R, monthly payment P, monthly income I, and days payment is late L.
a) If R, P, I are all sampled regularly, how would you visualize this data?
b) If all data is irregularly sampled, list three methods to visualize it.
9.8 Why do you think triangle strips are often faster to render than general polygons?
9.9 The normal generation technique described in this chapter creates consistently oriented surface normals.
a) Do the normals point inside or outside of a closed surface?
b) Describe a technique to orient normals so that they point out of a closed surface. c) Can surface normals be used to eliminate visible triangles prior to rendering? (Hint: what is the relationship between camera view and surface normal?)
9.10 Describe a technique to partially threshold a cell (i.e., to cut a cell as necessary to satisfy threshold criterion). Can an approach similar to marching cubes be used?
9.11 The class vtkRendererSource allows us to use the rendered image as a texture map (or image data dataset). Write a program to construct iterated textures, that is textures that consist of repeated images. Can the same image be generated using texture coordinates?
9.12 Describe how you would modify the decimation algorithm to treat general polygons.
9.13 Several examples in the text (e.g., deciFran.tcl and deciHawa.tcl) use the class vtkDecimate. Modify these examples to use the topology modifying progressive decimation algorithm (implemented in vtkDecimatePro). How much greater reduction can you achieve?