What is ParaView Catalyst?
ParaView Catalyst is an open-source software framework that empowers your simulations with cutting-edge in situ visualization and analysis capabilities, all while minimizing disruptions to your existing code. Its flexible, high-performance architecture enables in situ analysis on everything from desktop workstations to the most advanced exascale supercomputers, leveraging both CPUs and GPUs to deliver real-time, insight-rich visualizations that drive discovery and innovation.
Built upon the foundation of our award-winning ParaView architecture, ParaView Catalyst dramatically reduces the input/output (I/O) bottleneck that is commonly associated with traditional post-processing techniques.
By integrating visualization and analysis directly into your simulation workflow, ParaView Catalyst enables you to extract insights and understanding from your data in real time, without the need for time-consuming and resource-intensive data transfer and storage. This in situ approach not only accelerates your overall workflow but also opens up new possibilities for interactive exploration and steering of your simulations.
With its flexible and extensible design, ParaView Catalyst can be readily adapted to a wide range of simulation codes and computing environments. Whether you're working on a small-scale desktop simulation or a large-scale high-performance computing cluster, ParaView Catalyst can provide you with the tools you need to visualize and analyze your data in a way that is both efficient and effective.
What is the I/O Bottleneck?
In conventional post-processing approaches, the simulation will write out the information it wants processed to disk so that the post-processing tools can visualize it after the simulation has ended. This can significantly impact the simulation performance since I/O is orders of magnitude slower than the CPU or GPU cores being used by the simulation. In addition, the information associated with each timestep can be quite large. As a result, the simulation user typically will reduce the number of timesteps that are saved to disk which will impact the fidelity of the post-processed results.
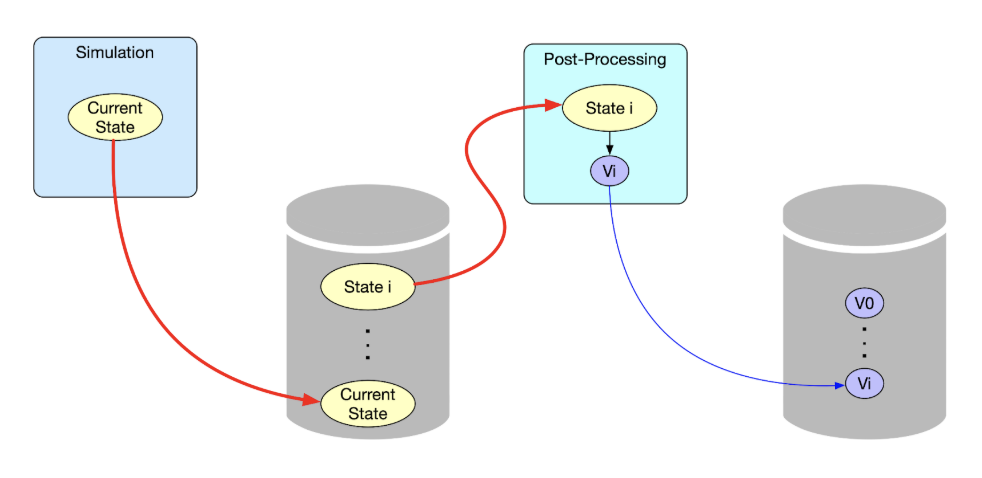
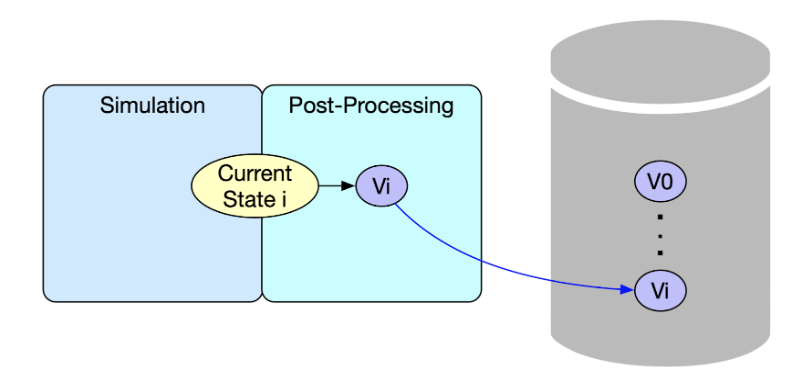
Attacking the I/O Problem
The in situ approach used by ParaView Catalyst addresses the I/O issue by performing the post-processing using the simulation in core; hence removing the need to write out timesteps to disk. This does not completely eliminate I/O associated with post-processing since the visualization information does need to be saved; however, the information associated with the post-processed result is significantly less than the original timestep information. This will allow the simulation to analyze more timesteps than the conventional approach in less time as shown in the video above.
How Does ParaView Catalyst Interface With the Simulation?
Introducing Catalyst, Conduit, and Mesh Blueprint
Your simulation code itself will not know about ParaView Catalyst but will be using a small easy to use library called Catalyst. The Catalyst library is written in C but also provides C++, Python, and FORTRAN wrappings. It provides the routines to initialize and finalize Catalyst as well as a routine to execute the processing of a timestep.
For representing the data associated with the simulation, Catalyst uses Conduit. Conduit, an open-source project developed by Lawrence Livermore National Laboratory, offers an intuitive model for representing hierarchical scientific data in C++, C, FORTRAN, and Python. Its applications include in-core data coupling between packages, serialization, and I/O operations.
Using Conduit, you can describe the structure of key pieces of the simulation. For example, how are the points, mesh elements, and fields represented. In most cases, this will not involve any data duplication and thereby will not impact the simulation’s memory footprint.
So where does ParaView Catalyst come in?
ParaView Catalyst is an implemented backend for Catalyst and is dynamically loaded at runtime. You will typically pass or hardwire a Python script describing the visualization/analysis you want performed when you initialized Catalyst and the backend will do all of the work for each timestep you execute.
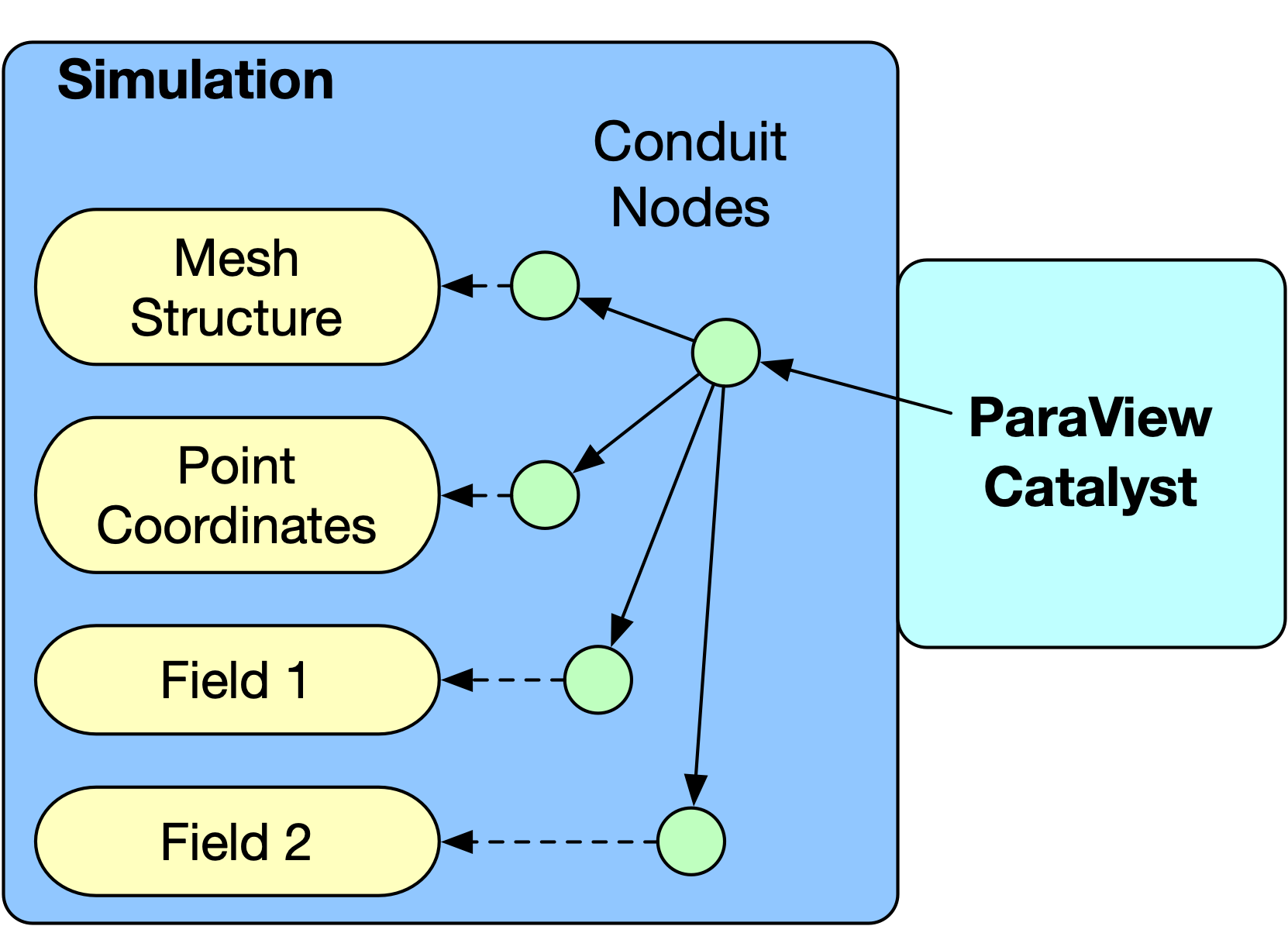
Making sure the simulation and the Catalyst Backend are on the same page - Mesh Blueprint
We have said that Conduit provides a flexible representation used to bridge between the solver and the Catalyst Backend, but how do we guarantee that the backend is interpreting the representation correctly? To ensure the Catalyst Backend correctly deciphers the flexible representation provided by Conduit, both sides must agree on and utilize a schema alongside the Conduit representation. In the case of ParaView Catalyst, the Mesh Blueprint specification fulfills this role.